本篇post以半监督文本分类为例,重点介绍如何通过对抗训练(Adversarial Training)的trick进一步提升系统性能。
对抗训练是一种用于监督式学习的正则化方法,虚拟对抗训练可将监督式学习的正则化方法扩展到半监督式中。上述两种正则化方法都需要对输入向量中的每个元素增加较小的扰动(perturbation)。 作者们通过将扰动加到word embeddings中(不是原始输入的one-hot向量),将上述两种正则化方法应用到文本领域中。实验表明,引入对抗训练和虚拟对抗训练可有效提高监督式和半监督式的任务的性能指标。
introduction
对抗样本是通过对输入进行细微扰动而创建的样本,其旨在显著增加模型的损失。大部分的模型都缺乏正确分类对抗样本的能力,有时甚至当对抗扰动被限制得很小以至于人类也无法感知的时候,模型仍无法正确区分。对抗训练就是训练模型正确区分正常样本和对抗样本的过程,其不仅提高了对对抗样本的鲁棒性,还提高了对正常样本的泛化性。 当以监督式训练模型时,对抗训练需使用标签。因为对抗扰动是通过最大化损失函数而确定的, 而监督式的损失函数中需要样本标签。虚拟对抗训练将对抗训练的思想扩展到半监督领域和无标签的样本中,其通过对模型进行正则化来实现。具体地,给定一个样本,模型可产生与该样本的对抗扰动所产生的输出分布相同的输出分布。虚拟对抗训练对监督式和半监督式任务均具有较好的泛化性能。
以前的工作主要是将对抗训练和虚拟对抗训练应用于图像分类任务中,作者们将其扩展到文本分类任务和序列模型。对文本分类来说,输入是离散的,通常表示为一系列高维独热(one-hot)向量。由于高维独热向量集不允许有微小的扰动,作者们将扰动(区别于随机扰动,其是一种用于增大损失的对抗扰动)加到了连续的词嵌入中,而不是离散的词输入上。 传统的对抗训练和虚拟对抗训练既可以解释为一种正则化方法,也可以看作是一种防御那些能提供恶意输入的对手的策略。由于扰动下的嵌入不会映射到任何单词,并且对手可能无法访问单词的嵌入层,因此作者们提出的训练策略不再是一种针对对手的防御策略,而仅是一种用来提高模型性能的正则化方法。
作者们证明,其提出的两种正则化方法应用在Semi-supervised Sequence Learning中提出的无监督预训练的神经语言模型上后,模型可在多个半监督的文本分类任务(包括情感分类和主题分类)上取得SOTA(state of the art)的性能。 作者们强调:仅优化一个额外的超参数,即限制对抗扰动大小的范数约束,就可实现SOTA(state of the art)的性能。同时作者们还指出这是其目前所知道的第一个使用对抗训练和虚拟对抗训练来改进文本或RNN模型的工作。
作者们还分析了训练后的模型,定性地描述了对抗训练和虚拟对抗训练的效果。作者们发现,对抗训练和虚拟对抗训练改善了传统方法的词嵌入。
model
由于作者们是在Semi-supervised Sequence Learning的基础上做的改进。首先简要说明下改进前的工作:
在Semi-supervised Sequence Learning中,作者们将无监督预训练得到的表示作为有监督训练的初始值,即半监督学习。其中监督式模型采用LSTM,无监督模型共有两种,一种是序列自编码器(SA-LSTM),一种是循环神经网络语言模型(LM-LSTM)。
序列自编码器(Sequence AutoEncoder)的模型结构如图所示:
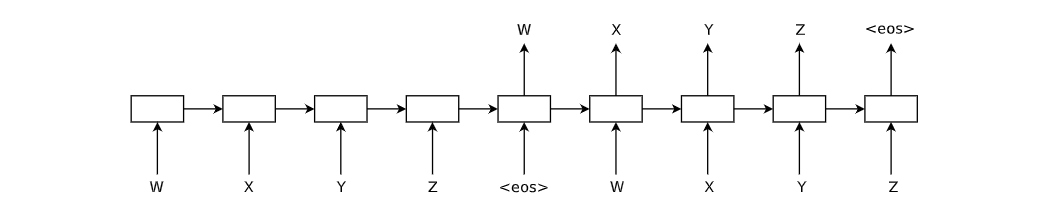
其是一种经典的seq2seq结构图,但输出和输入是一样的。 模型先利用大量无标签的数据进行无监督式预训练,然后将学习到的表示作为LSTM的初始值再进行有监督训练。一般用LSTM中的最后一个隐状态作为输出,同时作者们还尝试了将每个隐状态都作为输出,并将预测目标的权重从0线性增加到1。即linear label gain。上述两种思路都是将无监督和有监督分开训练,作者们也提供了一种联合训练的思路作为对比,称为joint learning。
将上图中的encoder部分去掉就得到了经典的语言模型, 即LM-LSTM的结构图。
作者们在情感分析、文本分类、目标分类等多组任务中进行了对比实验后发现,通过无监督式的预训练可有效改善监督模型的性能。
以上为改进前的工作小结。
以下为改进后的工作细节。
由introduction部分可知,所谓的对抗主要是在embedding的基础上增加扰动,具体图示如下:
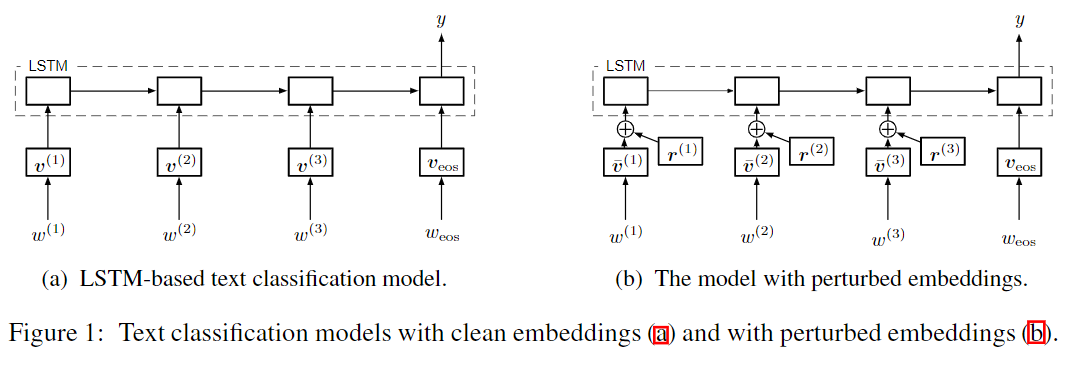
其中表示一个含有个词的序列,其相应的标签为。为词嵌入矩阵中第个word的embedding(词表中共有个词)。第个词的embedding为。图中,在每个时间步,输入为离散的词,其对应的连续的词嵌入为。
在对抗训练和虚拟对抗训练中,作者们训练分类器,使其对词嵌入的扰动具有鲁棒性,如图所示。关于扰动的确定后面会详细说明,目前只需理解扰动是有界范数。 模型为了使扰动变得微不足道,会趋向于学习具有非常大范数的词嵌入。 为了防止出现这种情况,当将对抗训练和虚拟对抗训练应用到上面的模型结构时,作者们将初始的词嵌入进行归一化为,具体转换过程为:
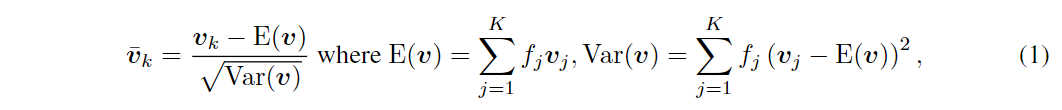
其中表示第个词的频率。
adversarial and virtual adversarial training
这部分详细说明如何确定上述扰动。
对抗训练是一种用于分类器的新颖的正则化方法。主要用于提高对微小的近似最坏情况的扰动的鲁棒性。当将对抗训练应用到分类器时,对抗训练对应的损失函数为(在原有损失函数的基础上又增加了一项):

其中为输入序列,为分类器(模型)的参数(由于无监督和监督式的模型的结构相同,因此其参数共享),为输入上的扰动,表示将分类器的当前参数设置为常数,即表明在构建对抗样本时,反向传播算法不会对当前模型参数进行更新。
在每一个训练步中,由方程确定对于当前模型的最坏情况的扰动,然后通过最小化方程中关于的损失函数,使模型对上述最坏情况的扰动具有一定的鲁棒性。
然而,对于许多模型(如神经网络)来说,精确的最小化是没法处理的。Explaining and harnessing adversarial examples中提出通过在附近线性化来近似最小值。 对方程进行线性近似并添加范数约束后,对应的对抗扰动为:
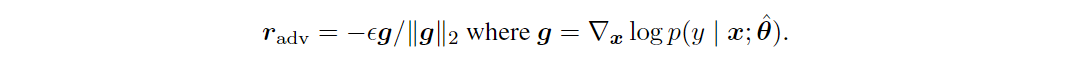
利用反向传播很容易计算出上述扰动。
虚拟对抗训练是一种与对抗训练密切相关的正则化方法。虚拟对抗训练对应的损失函数为(在原有损失函数的基础上又增加了一项):
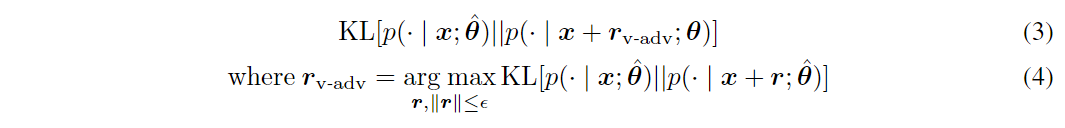
其中表示分布和分布间的KL散度。通过最小化方程,可平滑分类器。即保证分类器在当前模型最敏感的方向上不受干扰。注意到虚拟对抗训练对应的损失函数中不需要实际标签,仅需要输入,而方程中需要实际标签。因此,虚拟对抗训练可应用于半监督学习中。虽然我们通常无法分析计算虚拟对抗损失,但Distributional smoothing with virtual adversarial training中提出通过反向传播有效地计算方程的近似值。
基于上述两种扰动的近似分析,结合model部分中的图。
在对分类模型进行对抗训练时,作者们将对抗训练中的对抗扰动定义如下:

其中表示标准化后的word embedding向量序列的拼接。
针对式定义的对抗扰动,其对应的对抗损失为:

其中表示带有标签样本的数量。在作者们的实验中,对抗训练的目标函数为(negative log-likelihood)与的和,并通过SGD进行优化目标函数。
在对分类模型进行虚拟对抗训练时,作者们将虚拟对抗训练中的对抗扰动定义如下:

其中是一个维的小随机变量。与Distributional smoothing with virtual adversarial training中的工作类似,该近似值对应于式的二阶泰勒展开和幂方法的单次迭代。
针对式定义的对抗扰动,其对应的对抗损失为:

其中为有标签和无标签的样本总数。
还有其他形式的对抗训练方法,这里不再展开。
experiment
实验部分的代码详见:https://github.com/tensorflow/models/tree/master/research/adversarial_text
dataset
为了与其他文本分类方法进行对比,作者们在5个不同的文本数据集上进行测试。概要说明见下表:
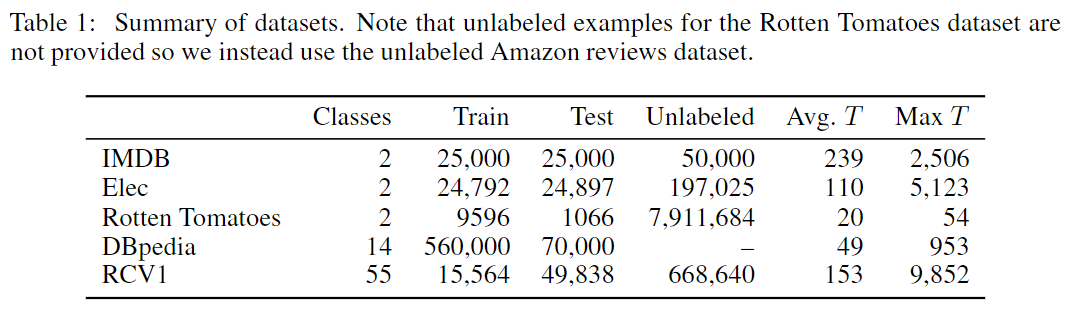
其中IMDB为用于情感分类的一个标准的基准电影评论数据集。Elec为亚马逊电子产品评论数据集。Rotten Tomatoes由简短的电影评论片段组成,也用于情感分类(其没有单独的测试集,作者们采用交叉验证的方式将其随机地分成90%的训练集和10%的测试集)。DBpedia为对维基百科页面进行类别分类的数据集(该数据集没有无类别标签的数据集,只能用于监督式学习)。RCV1由路透社的新闻报道组成,其用于主题分类。
关于预处理的说明
- 任何标点符号都视为空格
- Rotten Tomatoes、DBpedia和RCV1数据集上的所有单词转为小写
- 删除了在所有数据集中仅出现在一个文档中的单词
- 在RCV1数据集上,移除了英语的停用词
pretraining language model
与Semi-supervised Sequence Learning中的处理类似,作者们先利用有标签和无标签的样本预训练一个语言模型,然后将得到的word embedding矩阵和LSTM的权重作为分类模型的初始化值。下面简要说明下预训练模型的相关细节:
对单向单层的LSTM来说,其有1024个隐单元。对IMDB的数据集,词嵌入的维度为256;其他数据集,词嵌入的维度为512。训练时采用具有1024个候选样本的sampled softmax loss作为目标函数。优化时,采用Adam优化器,一个批次共256个样本,初始学习率为0.001,每个训练步的学习率的指数衰减因子为0.9999,共训练100,000步。在除词嵌入以外的所有参数上应用了范数为1的梯度裁剪。为了减少在GPU上的运行时间,使用了截断的反向传播。即反向传播时,从每个序列的末尾开始,最多反向传递400个词。为了正则化语言模型,对词嵌入矩阵进行0.5的dropout rate的操作。
对双向LSTM来说,其有512个隐单元。对所有数据集,词嵌入的维度为256。其他的超参数与单向的LSTM相同。作者们在IMDB、Elec和RCV数据集上测试双向LSTM模型,因为其有相对较长的句子。
使用预训练的参数可有效提升分类器在所有数据集的分类性能。但在预训练阶段不涉及对抗训练。
classification models
在上述预训练完成后,接着对图所示的文本分类模型进行对抗训练和虚拟对抗训练。其中两种对抗扰动的近似值已在adversarial and virtual adversarial training部分作了详细说明。下面简要说明下训练分类模型的相关细节:
在目标的softmax层和LSTM的最终输出之间,作者们添加了一个(全连接)隐层,该层在IMDB、Elec和Rotten Tomatoes上具有30维,在DBpedia和RCV1上具有128维。隐层的激活函数为ReLU。优化时依然使用Adam优化器,其初始学习率为0.0005,指数衰减率为0.9998。IMDB、Elec、RCV1的批处理大小为64,DBpedia的批处理大小为128。对于Rotten Tomatoes数据集,在每个训练步,作者们使用64的批大小来计算negative log-likelihood和对抗训练的损失,使用512的批大小计算虚拟对抗训练的损失。同样在Rotten Tomatoes数据集中,作者们在无标记的数据集中使用了长度小于25的文本。训练时,作者们在Elec、RCV1和Rotten Tomatoes上跑了10,000步,在IMDB上跑了15,000步,在DBpedia上跑了20,000步。再次对除词嵌入以外的所有参数上应用范数为1的梯度裁剪。同时也使用与预训练时相同的多达400个词长度的截断式的反向传播,并从序列的每一端生成了多达400个词的对抗扰动和虚拟对抗扰动。
当使用双向LSTM进行训练时,相比单向的LSTM,收敛的更慢些,实际训练时,作者们迭代了更多的步数。
针对每种数据集,作者们将原始训练集分为训练集和验证集以进一步优化各方法共享的超参数。针对每种方法,作者们使用验证集来优化词嵌入的dropout rate和两种对抗扰动的范数约束。值得说明的是,在进行对抗训练和虚拟对抗训练时,先对词嵌入进行dropout,在生成相应扰动,这样表现最好,且在扰动训练的过程中,没有做提前停止(early stopping)的操作。 将仅使用预训练和词嵌入的dropout的模型(方法)作为baseline。
results
IMDB
下图展示了baseline(仅包括预训练和embedding的dropout)、对抗训练和虚拟对抗训练三种不同方式在IMDB测试集上的学习曲线。
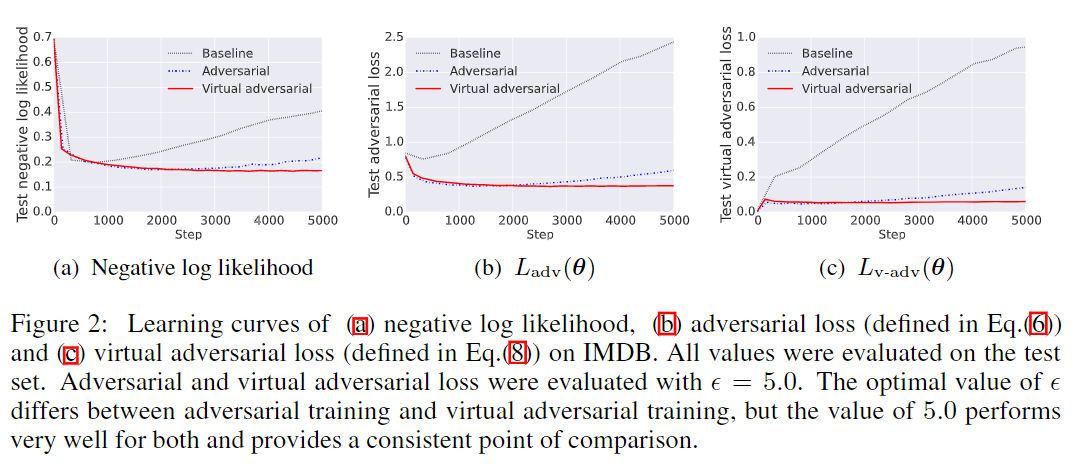
由图可知,对抗训练和虚拟对抗训练的负对数似然(negative log likelihood)比baseline低,并且虚拟对抗训练通过利用有标签和无标签的样本保持了较低的负对数似然,而其他两种方法只能利用有标签的样本,且随着训练步数的增多会出现过拟合现象。 而图和图中的对抗损失和虚拟对抗损失的学习曲线与图有相同的趋势。
下表展示了每种训练方法在IMDB测试集上的性能。
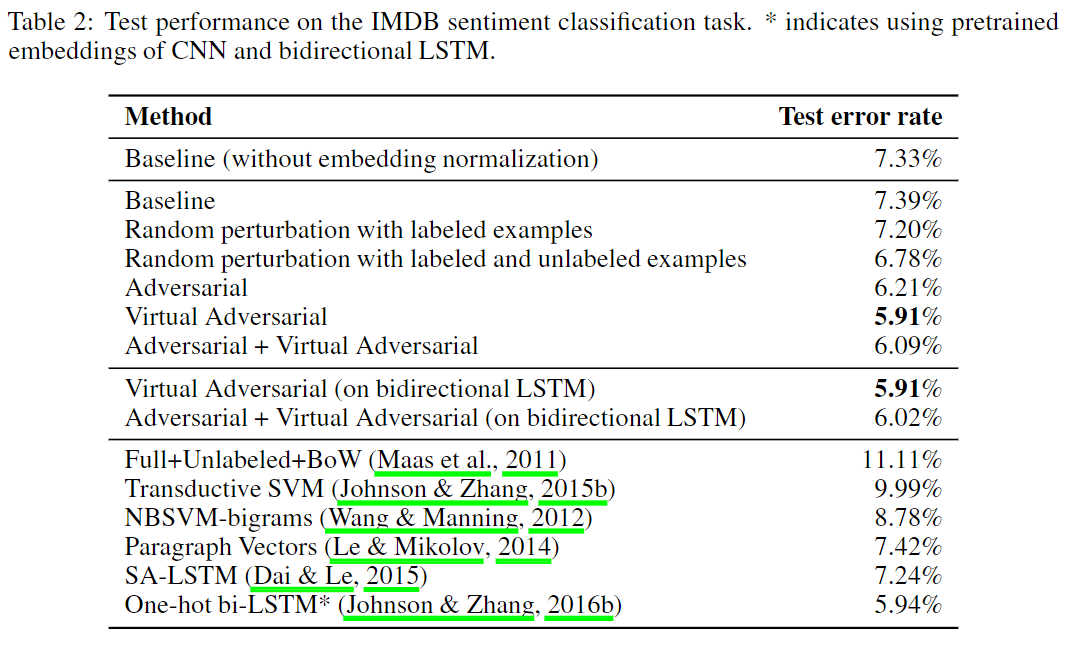
其中Adversarial + Virtual Adversarial指同时具有对抗损失和虚拟对抗损失的方法(两种损失共享范数约束)。baseline(只对embedding做dropout)可获得7.39%的错误率。对抗训练和虚拟对抗训练提升了baseline的性能,且虚拟对抗训练取得了SOTA的性能,错误率为5.91%。值得说明的是:先前SOTA的模型采用的是双向LSTM,而通过虚拟对抗得到的模型仅使用了单向的LSTM。 同时作者们也展示了虚拟对抗训练及Adversarial + Virtual Adversarial下双向LSTM的结果。
一个普遍的误解是:对抗训练等同于对有噪声(随机扰动)的样本进行训练。噪声(随机扰动)实际上是一种比对抗扰动弱得多的正则化器。因为在高维输入空间中,平均噪声向量与损失函数的梯度近似正交,而对抗扰动(向量)可持续地增大损失函数的值。 为了证明对抗训练相对于增加噪声的优势,作者们将输入序列对应的word embedding中的对抗扰动替换成带有标度范数的多元高斯随机扰动。表中的Random perturbation with labeled examples指将替换成随机扰动的方法。Random perturbation with labeled and unlabeled examples指将替换成随机扰动的方法。对比可知,每种对抗扰动的方法都优于每种随机扰动的方法。
为了可视化对抗训练和虚拟对抗训练对词嵌入的影响,作者们对比了不同方法训练得到的词嵌入。表展示了10个与good和bad最近邻的词嵌入。

由于语言模型的预训练,baseline和random方法都受到语言的语法结构的严重影响,但不受文本分类任务的语义的严重影响。例如,在baseline和random方法中,bad出现在good的最近邻列表中。bad和good都是可以修饰同一组名词的形容词,因此语言模型将其分配为相似的embedding是合理的,但这显然无法传达关于这些词的实际含义。但是对抗训练可确保句子的含义不会因为很小的变化而不同,因此那些具有相似语法功能但含义不同的词会被分开。 在adversarial和virtual adversarial中,bad不再出现在距离good最近邻的10个embedding中。 在adversarial中,bad排到good最近邻的19位;在virtual adversarial中,bad排到good最近邻的21位。在另一个方向上,在baseline和random方法中,good排在bad最近邻的第4位;在adversarial和virtual adversarial中,good排在bad最近邻的第36位。综上所述,通过对抗扰动和虚拟对抗扰动的方法,有效改善了word embedding的质量。
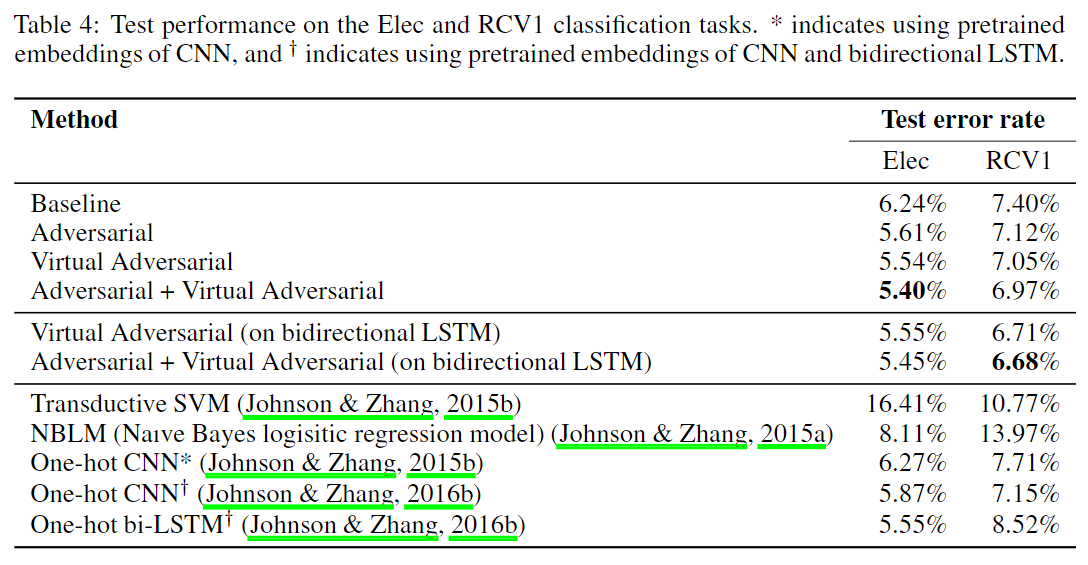
Elec and RCV1
下表展示了每种训练方法在Elec和RCV1测试集上的性能。
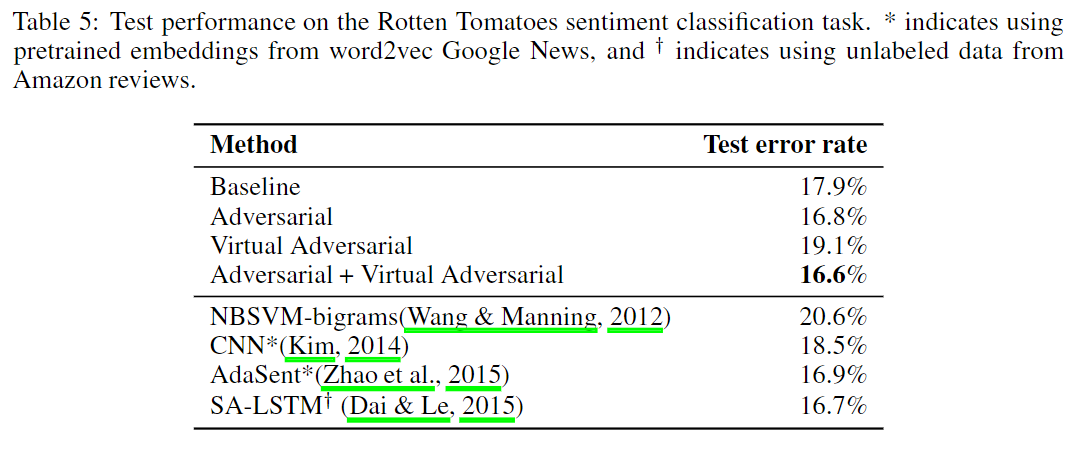
DBpedia
下表展示了每种训练方法在DBpedia测试集上的(纯监督式的分类)性能。
conclusion
由上述实验可知,对抗训练和虚拟对抗训练在文本分类任务的序列模型中具有良好的正则化性能,同时还改善了词嵌入的质量。作者们提出的对抗训练的方法有望用于其他文本领域的任务,如机器翻译、词或段落的分布式表示以及问答任务。也可用于其他通用的序列任务,如视频或语音。