背景
之前梳理过关于机器阅读理解的相关内容,这里主要记录如何通过数据增强的trick来进一步提升性能指标。
当答案为文档中的一个连续片段(可看成一种实体)时,系统已可十分准确地从文档中抽取答案。但当给定文档中无法找到某个问题的答案时,系统应拒绝回答。而这类无法回答的问题的难度相比可抽取片段(实体)的问题要大,且数量较少。
针对上述问题,Learning to Ask Unanswerable Questions for Machine Reading Comprehension中提出seq2seq与pair2seq的模型,利用可回答问题与相应段落来生成不可回答问题。实验表明,增强后的数据可有效提升系统的性能。
数据观察
SQuAD 2.0数据集中新增的无法回答问题,有一个似是而非(plausible)的答案;而这个似是而非的答案也是某个可回答问题的答案。即一个答案对应两种问题,一种是可回答的,一种是无法回答的。 示意图如下:

基于上述观察,可将一个答案两种问题的数据集构造成(可回答问题,对应段落,对应答案,不可回答问题)的四元组形式,以构造的四元组样本集为训练集进行数据增强。其中源输入为可回答问题和对应段落,目标输出为不可回答问题。
问题描述
给定可回答的问题和包含答案的段落,生成不可回答的问题。生成的不可回答问题需满足如下要求
- 问题在段落中找不到答案
- 问题需要与可回答的问题和段落都相关,这可避免产生不相关的问题
- 问题需问一些和答案相关的问题。
基于上述要求,Learning to Ask Unanswerable Questions for Machine Reading Comprehension中研究了两种基于编码器-解码器结构的神经网络模型(用于生成不可回答的问题)。示意图如下:
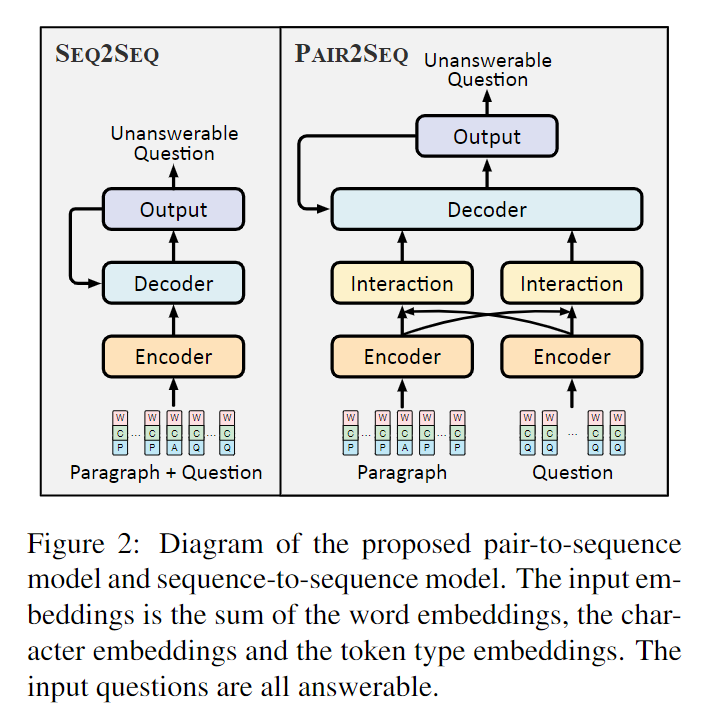
其中seq2seq模型将拼接后的段落与问题作为输入,并以序列的方式进行编码。而pair2seq模型先对段落和问题分别编码,然后基于注意力机制捕获问题和段落间的交互,得到基于问题的段落表示和基于段落的问题表示,两种表示共同用于解码。(为了能够更有效地利用输入的问题和段落来生成无法回答的问题,在解码时还采用复制机制,将输入序列中的token复制到输出中。)
上述两种模型的解码器依次解码出无法回答的问题,其生成概率为。由语言模型可将此概率分解为:
其中
seq2seq
seq2seq模型的输入序列的embedding层由word embeddings、character embeddings和token type embeddings三部分组成,三部分的和为embedding层的输出,且第个token对应的embedding记为。 其中token type是为了区分段落与问题,有answer(A)、paragraph(P)和question(Q)三种类型;character embeddings是通过对word embeddings进行最大池化操作所得。
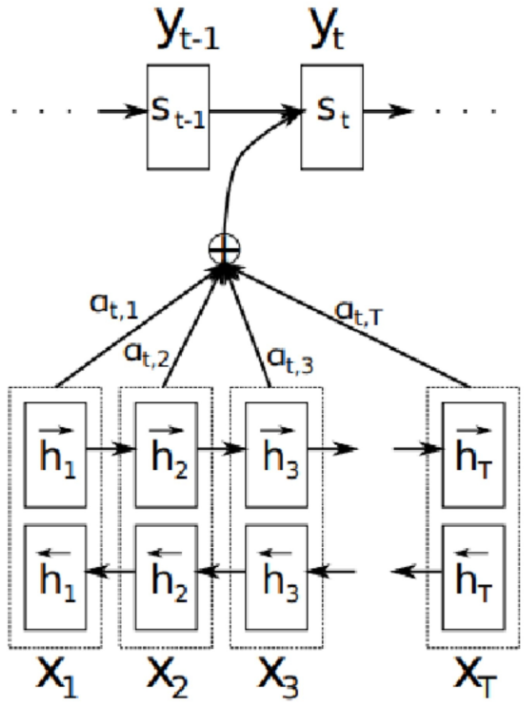
encoder层为单层双向的LSTM,其隐状态。decoder层为单层单向的LSTM,其隐状态。其中表示时刻对应的解码输出,表示时刻解码器对应的语义编码,该语义编码是基于attention机制对编码器中的隐状态求和得到的。关于语义编码的相关计算如下所示:
其中表示隐状态的权重,表示与相关性得分,,为可学习的参数。
图示说明如下:
基于上述的与可确定生成每个词汇对应的概率:
其中与为可学习的参数。
由于段落中的词或可回答问题中的词对生成无法回答的问题很有参考价值,因此引入复制机制,直接从输入部分复制词。具体地,通过与生成一个门控概率:
其中与为可学习的参数。决定了生成的词是从词表中选的还是从输入部分复制的。
最终得到生成词的概率为:
其中表示词在输入序列中出现的所有位置索引的集合。的计算方式与相同但参数不同。
pair2seq
段落与问题的交互在机器阅读理解中起着至关重要的作用。交互使段落和问题相互意识到彼此,从而有助于更准确地预测答案。基于上述事实,提出了一种pair2seq的模型。
pair2seq模型的embedding层将段落和问题分别编码为和,encoder层是两个共享权重的单层双向LSTM,基于embedding层的输入可分别得到段的隐状态和问题的隐状态。interaction层使用和seq2seq模型中同样的attention机制分别生成意识到问题的段落表示和意识到段落的问题表示。
关于的具体公式为:
其中表示问题序列中个token相对于段落中的第个token的语义表示(类似于seq2seq中的)。表示问题序列中每个token对应的权重。。与为可学习的参数。
相似地,关于的具体公式为:
其中表示段落序列中个token相对于问题中的第个token的语义表示(类似于seq2seq中的)。表示段落序列中每个token对应的权重。。与为可学习的参数。
decoder层为单层单向LSTM,其隐状态为
其中与分别表示段落的语义编码和问题的语义编码,其计算方式与类似。
接下来的预测词和复制机制的部分与seq2seq相同。
训练与推断
上述两个模型在训练阶段的目标是在给定可回答问题和包含答案的段落的条件下,使生成的无法回答的问题与给定的无法回答问题尽可能相似。使下述目标函数最小:
其中表示训练语料,表示模型中所有的可学习参数。
推断时,表示生成的最有可能的无法回答的问题序列为。同时,为了避免遍历所有可能的输出,同时保证生成的多样性,在生成时使用了Beam search。
实验结果
生成质量的评估结果如下图所示:
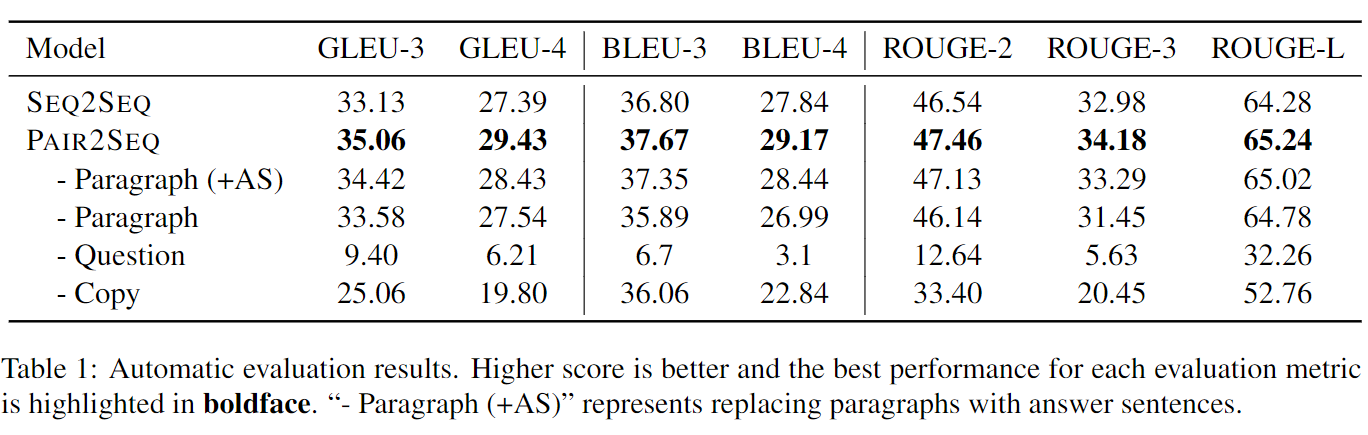
可看出pair2seq相比seq2seq的生成质量更好的无法回答类问题。且输入的可回答问题对生成质量起着重要作用。
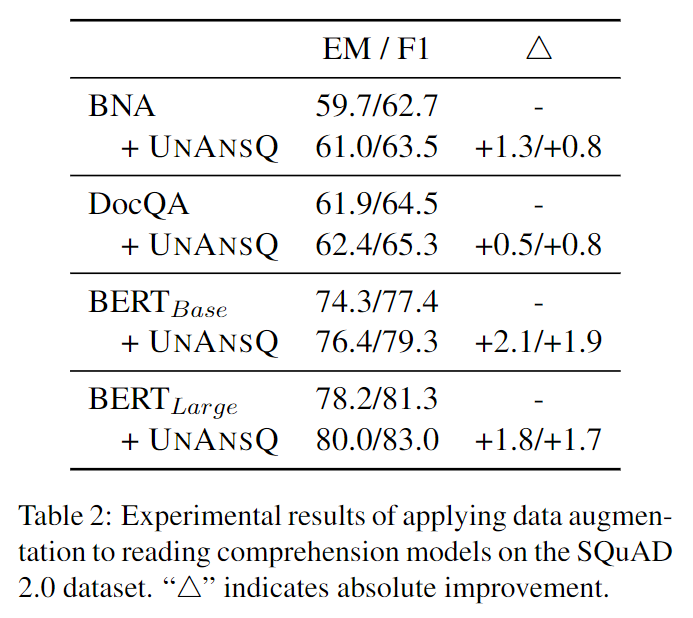
下图给出了在现有模型基础上通过增强无法回答问题的数量,EM与F1两个性能指标都有所提高。
下图展示了对生成的无法回答的问题从不可回答性、相关性及可读性三个方面的人工评价结果。
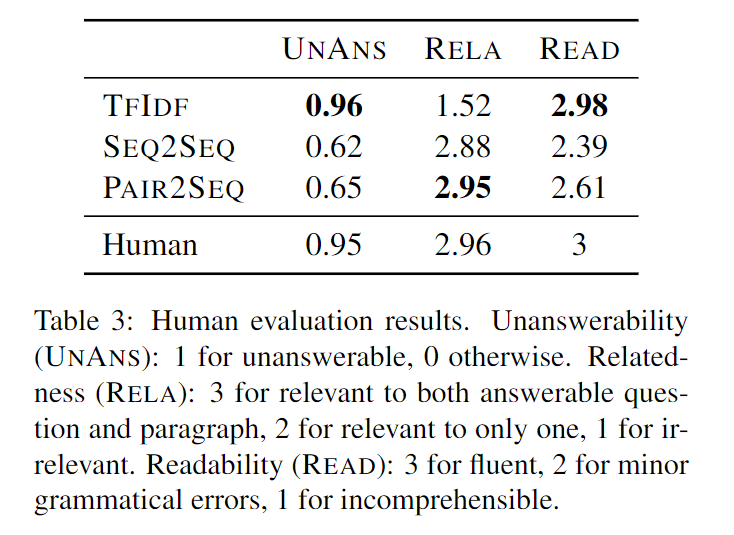
其中TFIDF的方法为baseline,其使用输入的可回答问题来检索对其他文章的类似问题作为输出。这种方式检索出的问题大多是不可回答且可读的,但和输入的段落与问题十分不相关。
SQuAD2.0数据集中原有的不可回答的问题有六类,下图统计了生成的不可回答问题的类型分布情况。
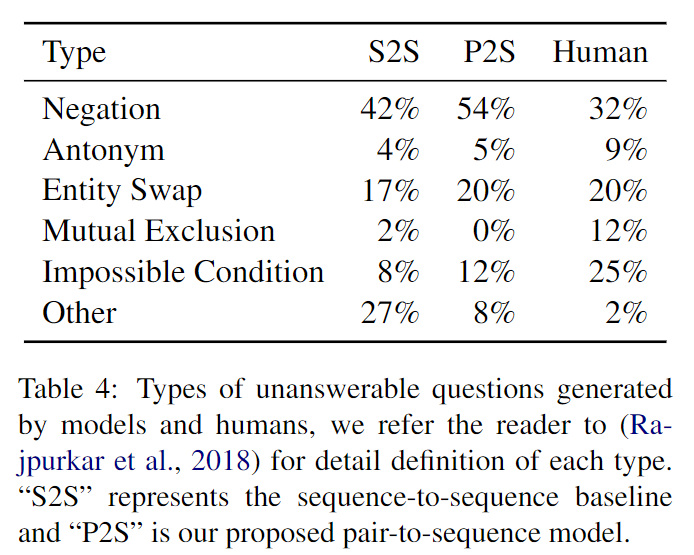
其中自动生成的不可回答问题主要由加入否定词和实体替换两类组成,相比原有的问题类型分布有点单一。
下图对比了不同的生成无法回答问题的方法的效果。
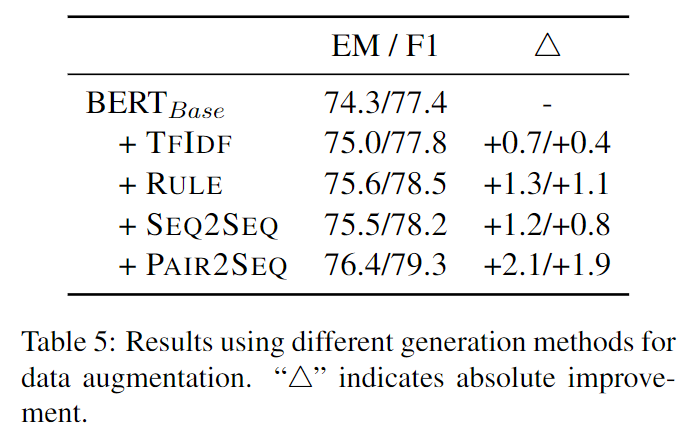
有使用TF-IDF来检索其他文档的问题的方法;在可回答问题中加入反义词、替换实体等基于规则的方法,对比各种方法可看出pair2seq的性能最好。
同时为了检验增强数据的规模对阅读理解系统的影响,通过beam search方法为每个输入生成多个不可回答的问题。
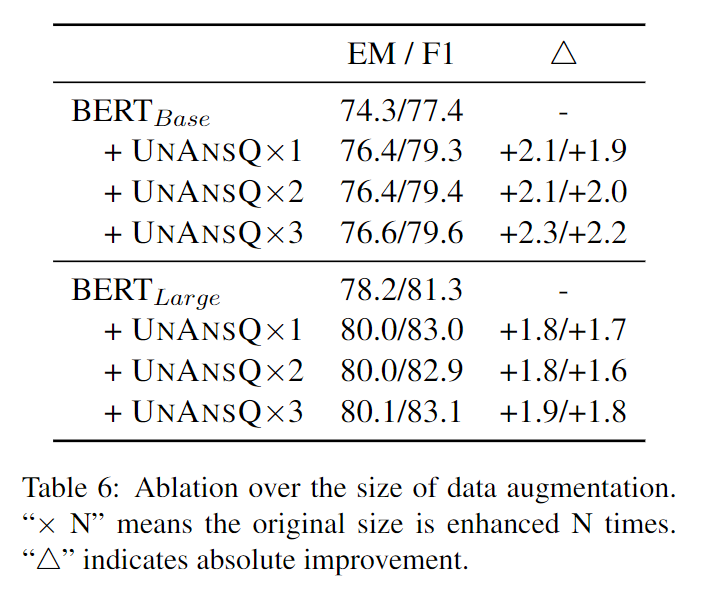
在BERT-base和BERT-large模型上进行实验,结果如下表所示,在较小的BERT-base模型上,扩大增强数据规模能够取得进一步的提升,但数据规模对BERT-large模型几乎没有影响。