推荐使用 tensorflow 1.13版本
pip install --index-url https://pypi.douban.com/simple tensorflow==1.13.2
以经典的鸢尾花分类任务为导向,通过简单的三层神经网络模型总结tensorflow(1.x)中模型的保存与使用。
涉及的主要主要知识点有高阶estimator(tf.train.LoggingTensorHook、tf.estimator.Estimator().export_savedmodel)、低阶session(tf.train.Saver().saver/tf.train.Saver().restore、tf.saved_model.builder.SavedModelBuilder(model_path).save/tf.saved_model.loader.load)、tf.data、tf.feature_column、tf.trainable_variables、SavedModel CLI及tensorflow serving等。
数据集简介
Iris(鸢尾花)一共包含150个样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
样本按4:1的比例被分成两个文件,具体如下:
custom estimator
先mark下高阶estimator的优势:
- 由单机向分布式过渡时代码变动少
- 代码简单直观
- 有预创建模型可以直接使用
- 可以配合feature_column进行特征工程,简化线上操作,也不用顾忌线上线下模型不一致的问题。使用feature_column可以直接接受原始特征,虽然可以带来性能问题,但对于快速试验模型来说是非常友好的。
- 模型保存,导出,部署相对简洁
- 与tensorboard配合良好
- TensorFlow团队推荐使用,也是其开发重点
接着看下tensorflow官网给出的基于custom_estimator的指导说明。 具体的代码说明及运行流程官方文档及博客已经有详细说明。这里记录下在基于estimator框架开发模型时的调试与部署方面的内容。
调试
关于调试,如果想在每一个训练步上监控相关变量(输入特征/标签、模型权重、性能指标等)的输出,可利用tf.train.LoggingTensorHook进行相关变量的配置,示例代码如下:
def my_model(features, labels, mode, params):
"""DNN with three hidden layers and learning_rate=0.1."""
# Create three fully connected layers.
net = tf.feature_column.input_layer(features, params['feature_columns'])
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
# Compute logits (1 per class).
logits = tf.layers.dense(net, params['n_classes'], activation=None)
# Compute predictions.
predicted_classes = tf.argmax(logits, 1)
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis],
'probabilities': tf.nn.softmax(logits),
'logits': logits,
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
# Compute loss.
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
# Compute evaluation metrics.
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op')
metrics = {'accuracy': accuracy}
tf.summary.scalar('accuracy', accuracy[1])
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=metrics)
# Create training op.
assert mode == tf.estimator.ModeKeys.TRAIN
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1)
global_step=tf.train.get_global_step()
train_op = optimizer.minimize(loss, global_step=global_step)
# add trainable_variables
tvars = tf.trainable_variables()
for var in tvars:
print(f'name = {var.name}, shape = {var.shape}, value = {var.value}')
# add LoggingTensorHook
tensors_log = {
'global_step': global_step,
'acc': accuracy[1],
'loss': loss,
'labels': labels,
# tvars[1].name: tvars[1].value(), # 监控动态权重参数
}
training_hooks = tf.train.LoggingTensorHook(
tensors=tensors_log, every_n_iter=1)
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op, training_hooks=[training_hooks])
部署
关于部署,tensorflow官方提供了tensorflow serving,其要求模型文件为SavedModel格式。
SavedModel格式特性
-
SavedModel不仅记录了模型中所有参数(tf.Variable对象)的值,还包括模型中计算操作的序列化描述。这种格式的模型独立于创建模型的源代码。因此,SavedModel适合通过TensorFlow Serving、TensorFlow Lite、TensorFlow.js或其他编程语言进行部署。
-
SavedModel 是一种跨语言的序列化格式(protobuf),可以保存和加载模型变量、图和图的元数据,适用于将训练得到的模型保存用于生产环境中的预测过程。由于跨语言的特性,应用时,可以使用一种语言保存模型,如训练时使用Python代码保存模型;使用另一种语言恢复模型,如使用C++代码恢复模型,进行前向推理,提高效率。
-
SavedModel可以为保存的模型添加签名(SignatureDef),用于保存指定输入输出的graph, 另外可以为模型中的输入输出tensor指定别名,这样使用模型的时候就不必关心训练阶段模型的输入输出tensor具体的name是什么,将模型的训练和部署解耦,更加方便。
export_savedmodel
export_savedmodel可将训练好的模型导出成SavedModel格式。伪代码如下:
estimator.export_savedmodel(export_dir_base, serving_input_receiver_fn)
其中serving_input_receiver_fn表示tensorflow serving接收请求输入(并做相应处理)的函数,该函数返回一个 tf.estimator.export.ServingInputReceiver 对象。serving_input_receiver_fn可自定义,也可直接利用tensorflow封装好的API(tf.estimator.export.build_parsing_serving_input_receiver_fn或tf.estimator.export.build_raw_serving_input_receiver_fn)。build_parsing_serving_input_receiver_fn用于接收序列化的tf.Examples。而build_raw_serving_input_receiver_fn用于接收原生的Tensor。 详情可查看官网API。
下面给出两种不同输入方式下,导出训练好的鸢尾花分类模型的代码:
# saved_model_cli run --input_expr
classifier.export_savedmodel(args.raw_export_dir, raw_serving_input_fn, as_text=False)
# saved_model_cli run --input_examples
# feature规范(解析规范),指明解析序列化的example时需遵循的解析规范
feature_spec = tf.feature_column.make_parse_example_spec(feature_columns=my_feature_columns)
parsing_serving_input_fn = tf.estimator.export.build_parsing_serving_input_receiver_fn(feature_spec)
classifier.export_savedmodel(args.parsing_export_dir, parsing_serving_input_fn, as_text=False)
其中raw_serving_input_fn为
def raw_serving_input_fn():
SepalLength = tf.placeholder(tf.float32, [None], name='SepalLength')
SepalWidth = tf.placeholder(tf.float32, [None], name='SepalWidth')
PetalLength = tf.placeholder(tf.float32, [None], name='PetalLength')
PetalWidth = tf.placeholder(tf.float32, [None], name='PetalWidth')
input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({
'SepalLength': SepalLength,
'SepalWidth': SepalWidth,
'PetalLength': PetalLength,
'PetalWidth': PetalWidth,
})()
return input_fn
导出的模型目录结构如下
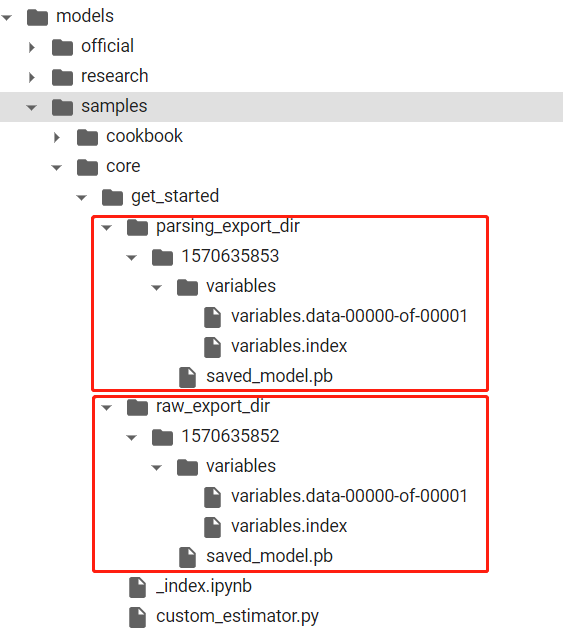
完整代码如下:https://github.com/carlos9310/models/blob/master/samples/core/get_started/custom_estimator.py
SavedModel CLI
show
接下来,通过SavedModel CLI(saved_model_cli命令行工具在安装tensorflow时已装好)检查导出的模型。
首先看下parsing_export_dir中模型的输入、输出与函数名(signature_def)
!saved_model_cli show --dir /content/models/samples/core/get_started/parsing_export_dir/1570635853 --all
输出
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['examples'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: input_example_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['class_ids'] tensor_info:
dtype: DT_INT64
shape: (-1, 1)
name: strided_slice:0
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 3)
name: dense_2/BiasAdd:0
outputs['probabilities'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 3)
name: Softmax:0
Method name is: tensorflow/serving/predict
其中signature_def与output(s)在EstimatorSpec类中的export_outputs参数上指定。因export_outputs=None,则signature_def=tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY,PredictOutput被映射到EstimatorSpec中的predictions。具体说明参见官方tf.estimator.EstimatorSpec
而input(s)则与build_parsing_serving_input_receiver_fn中的receiver_tensors对应,具体代码如下:
def build_parsing_serving_input_receiver_fn(feature_spec,
default_batch_size=None):
"""Build a serving_input_receiver_fn expecting fed tf.Examples.
Creates a serving_input_receiver_fn that expects a serialized tf.Example fed
into a string placeholder. The function parses the tf.Example according to
the provided feature_spec, and returns all parsed Tensors as features.
Args:
feature_spec: a dict of string to `VarLenFeature`/`FixedLenFeature`.
default_batch_size: the number of query examples expected per batch.
Leave unset for variable batch size (recommended).
Returns:
A serving_input_receiver_fn suitable for use in serving.
"""
def serving_input_receiver_fn():
"""An input_fn that expects a serialized tf.Example."""
serialized_tf_example = array_ops.placeholder(
dtype=dtypes.string,
shape=[default_batch_size],
name='input_example_tensor')
receiver_tensors = {'examples': serialized_tf_example}
features = parsing_ops.parse_example(serialized_tf_example, feature_spec)
return ServingInputReceiver(features, receiver_tensors)
至于tag-set: ‘serve’在哪指定的有待确定。
再看下raw_export_dir中模型的输入、输出与函数名(signature_def)
!saved_model_cli show --dir /content/models/samples/core/get_started/raw_export_dir/1570635852 --all
输出
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['PetalLength'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: PetalLength_1:0
inputs['PetalWidth'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: PetalWidth_1:0
inputs['SepalLength'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: SepalLength_1:0
inputs['SepalWidth'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: SepalWidth_1:0
The given SavedModel SignatureDef contains the following output(s):
outputs['class_ids'] tensor_info:
dtype: DT_INT64
shape: (-1, 1)
name: strided_slice:0
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 3)
name: dense_2/BiasAdd:0
outputs['probabilities'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 3)
name: Softmax:0
Method name is: tensorflow/serving/predict
其中input(s)与build_raw_serving_input_receiver_fn中features相对应。
run
然后通过CLI执行导出的SavedModel
parsing:
!saved_model_cli run --dir /content/models/samples/core/get_started/parsing_export_dir/1570635853 --tag_set serve --signature_def "serving_default" --input_examples "examples=[{'SepalLength':[5.1],'SepalWidth':[3.3],'PetalLength':[1.7],'PetalWidth':[0.5]},{'SepalLength':[5.9],'SepalWidth':[3.0],'PetalLength':[4.2],'PetalWidth':[1.5]},{'SepalLength':[6.9],'SepalWidth':[3.1],'PetalLength':[5.4],'PetalWidth':[2.1]}]"
输出
Result for output key class_ids:
[[0]
[1]
[2]]
Result for output key logits:
[[ 14.050745 7.529233 -20.961254 ]
[ -8.585186 1.605782 -5.615126 ]
[-19.447586 -1.3812836 1.3279335]]
Result for output key probabilities:
[[9.9853075e-01 1.4692806e-03 6.2207476e-16]
[3.7478767e-05 9.9923193e-01 7.3057652e-04]
[8.8983432e-10 6.2431667e-02 9.3756837e-01]]
raw:
!saved_model_cli run --dir /content/models/samples/core/get_started/raw_export_dir/1570635852 --tag_set serve --signature_def "serving_default" --input_expr 'SepalLength=[5.1,5.9,6.9];SepalWidth=[3.3,3.0,3.1];PetalLength=[1.7,4.2,5.4];PetalWidth=[0.5,1.5,2.1]'
输出
Result for output key class_ids:
[[0]
[1]
[2]]
Result for output key logits:
[[ 14.050745 7.529233 -20.961254 ]
[ -8.585186 1.605782 -5.615126 ]
[-19.447586 -1.3812836 1.3279335]]
Result for output key probabilities:
[[9.9853075e-01 1.4692806e-03 6.2207476e-16]
[3.7478767e-05 9.9923193e-01 7.3057652e-04]
[8.8983432e-10 6.2431667e-02 9.3756837e-01]]
tensorflow serving
下面看下如何通过serving访问模型
首先是tensorflow serving的安装,官方推荐用docker安装,但本人在colab上测试,直接安装的是python的包,具体步骤如下:
先将TensorFlow Serving发行版的URI添加到软件包源
# This is the same as you would do from your command line, but without the [arch=amd64], and no sudo
# You would instead do:
# echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list && \
# curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add -
!echo "deb http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | tee /etc/apt/sources.list.d/tensorflow-serving.list && \
curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | apt-key add -
!apt update
再安装tensorflow serving软件包
!apt-get install tensorflow-model-server
然后就可以运行tensorflow serving的服务了。
下面分别记录如何访问接收原生tensor格式和序列化的tf.Example格式的导出模型。
- TensorFlow Serving for raw_export_dir
- 将导出的接收原生tensor的模型的路径添加到环境变量中
import os os.environ["MODEL_DIR"] = '/content/models/samples/core/get_started/raw_export_dir/' - 启动服务
%%bash --bg nohup tensorflow_model_server \ --port=8500 \ --rest_api_port=8501 \ --model_name=raw_export_model \ --model_base_path=${MODEL_DIR} >server.log 2>&1 - 查看服务启动日志
!tail server.log
- 将导出的接收原生tensor的模型的路径添加到环境变量中
REST for raw tensor
组织数据
import json
feature_dict1 = {'SepalLength':[5.1],'SepalWidth':[3.3],'PetalLength':[1.7],'PetalWidth':[0.5]}
feature_dict2 = {'SepalLength':[5.9],'SepalWidth':[3.0],'PetalLength':[4.2],'PetalWidth':[1.5]}
feature_dict3 = {'SepalLength':[6.9],'SepalWidth':[3.1],'PetalLength':[5.4],'PetalWidth':[2.1]}
# json字符串
data = json.dumps({"signature_name": "serving_default","instances": [feature_dict1,feature_dict2,feature_dict3] })
# json对象
# data = {"signature_name": "serving_default","instances": [feature_dict1,feature_dict2,feature_dict3] }
print(data)
发送请求
!pip install -q requests
import requests
json_response = requests.post('http://localhost:8501/v1/models/raw_export_model:predict', data=data ) #json字符串
# json_response = requests.post('http://localhost:8501/v1/models/raw_export_model:predict', json=data ) #json对象
predictions = json.loads(json_response.text)
predictions
GRPC for raw tensor
安装客户端的包
# 需在tensorflow-model-server之后安装!!
!pip install tensorflow-serving-api=='1.12.0'
客户端的访问代码
from __future__ import print_function
import grpc
import requests
import tensorflow as tf
import numpy as np
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel(target='0.0.0.0:8500')
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'raw_export_model'
request.model_spec.signature_name = 'serving_default'
request.inputs['SepalLength'].CopyFrom(tf.contrib.util.make_tensor_proto([5.1,5.9,6.9], shape=[3]))
request.inputs['SepalWidth'].CopyFrom(tf.contrib.util.make_tensor_proto([3.3,3.0,3.1], shape=[3]))
request.inputs['PetalLength'].CopyFrom(tf.contrib.util.make_tensor_proto([1.7,4.2,5.4], shape=[3]))
request.inputs['PetalWidth'].CopyFrom(tf.contrib.util.make_tensor_proto([0.5,1.5,2.1], shape=[3]))
result = stub.Predict(request, 10.0) # 10 secs timeout ['logistic']
# result
outputs_tensor_proto = result.outputs["logits"]
shape = tf.TensorShape(outputs_tensor_proto.tensor_shape)
outputs = tf.constant(list(outputs_tensor_proto.float_val), shape=shape)
outputs = np.array(outputs_tensor_proto.float_val).reshape(shape.as_list())
print(f'logits:{outputs}')
- TensorFlow Serving for parsing_export_dir
- 将导出的接收序列化tf.Examples的模型的路径添加到环境变量中
import os os.environ["MODEL_DIR"] = '/content/models/samples/core/get_started/parsing_export_dir/' - 启动服务
%%bash --bg nohup tensorflow_model_server \ --port=9500 \ --rest_api_port=9501 \ --model_name=parsing_export_model \ --model_base_path=${MODEL_DIR} >server.log 2>&1 - 查看服务启动日志
!tail server.log
- 将导出的接收序列化tf.Examples的模型的路径添加到环境变量中
REST for serialized_tf_example
组织数据
import tensorflow as tf
import json
import base64
# 生成tf.Example 数据
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
feature_dict1 = {'SepalLength':_float_feature(5.1),'SepalWidth':_float_feature(3.3),'PetalLength':_float_feature(1.7),'PetalWidth':_float_feature(0.5)}
feature_dict2 = {'SepalLength':_float_feature(5.9),'SepalWidth':_float_feature(3.0),'PetalLength':_float_feature(4.2),'PetalWidth':_float_feature(1.5)}
feature_dict3 = {'SepalLength':_float_feature(6.9),'SepalWidth':_float_feature(3.1),'PetalLength':_float_feature(5.4),'PetalWidth':_float_feature(2.1)}
example_proto_1 = tf.train.Example(features=tf.train.Features(feature=feature_dict1))
serialized_1 = example_proto_1.SerializeToString()
example_proto_2 = tf.train.Example(features=tf.train.Features(feature=feature_dict2))
serialized_2 = example_proto_2.SerializeToString()
example_proto_3 = tf.train.Example(features=tf.train.Features(feature=feature_dict3))
serialized_3 = example_proto_3.SerializeToString()
# json字符串
# data = json.dumps({"signature_name": "serving_default","instances": [{'examples':{'b64':base64.b64encode(serialized_1).decode()}},{'examples':{'b64':base64.b64encode(serialized_2).decode()}},{'examples':{'b64':base64.b64encode(serialized_3).decode()}}] })
# json对象 参考https://stackoverflow.com/questions/51776489/correct-payload-for-tensorflow-serving-rest-api
data = {"signature_name": "serving_default","instances": [{'examples':{'b64':base64.b64encode(serialized_1).decode()}},{'examples':{'b64':base64.b64encode(serialized_2).decode()}},{'examples':{'b64':base64.b64encode(serialized_3).decode()}}] }
print(data)
发送请求
!pip install -q requests
import requests
# json_response = requests.post('http://localhost:9501/v1/models/parsing_export_model:predict', data=data ) #json字符串
json_response = requests.post('http://localhost:9501/v1/models/parsing_export_model:predict', json=data ) #json对象
predictions = json.loads(json_response.content)# .text
predictions
GRPC for serialized_tf_example
安装客户端的包
# 需在tensorflow-model-server之后安装!!
!pip install tensorflow-serving-api=='1.12.0'
客户端的访问代码
from __future__ import print_function
import grpc
import requests
import tensorflow as tf
import numpy as np
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
# 生成tf.Example 数据
def _float_feature(value):
"""Returns a float_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
channel = grpc.insecure_channel(target='0.0.0.0:9500')
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'parsing_export_model'
request.model_spec.signature_name = 'serving_default'
serialized_strings = []
feature_dict1 = {'SepalLength':_float_feature(5.1),'SepalWidth':_float_feature(3.3),'PetalLength':_float_feature(1.7),'PetalWidth':_float_feature(0.5)}
feature_dict2 = {'SepalLength':_float_feature(5.9),'SepalWidth':_float_feature(3.0),'PetalLength':_float_feature(4.2),'PetalWidth':_float_feature(1.5)}
feature_dict3 = {'SepalLength':_float_feature(6.9),'SepalWidth':_float_feature(3.1),'PetalLength':_float_feature(5.4),'PetalWidth':_float_feature(2.1)}
example_proto_1 = tf.train.Example(features=tf.train.Features(feature=feature_dict1))
serialized_1 = example_proto_1.SerializeToString()
serialized_strings.append(serialized_1)
example_proto_2 = tf.train.Example(features=tf.train.Features(feature=feature_dict2))
serialized_2 = example_proto_2.SerializeToString()
serialized_strings.append(serialized_2)
example_proto_3 = tf.train.Example(features=tf.train.Features(feature=feature_dict3))
serialized_3 = example_proto_3.SerializeToString()
serialized_strings.append(serialized_3)
data = serialized_strings
size = len(data)
request.inputs['examples'].CopyFrom(tf.contrib.util.make_tensor_proto(data, shape=[size]))
result = stub.Predict(request, 10.0) # 10 secs timeout
print(type(result))
# print(result)
outputs_tensor_proto = result.outputs["logits"]
shape = tf.TensorShape(outputs_tensor_proto.tensor_shape)
outputs = tf.constant(list(outputs_tensor_proto.float_val), shape=shape)
outputs = np.array(outputs_tensor_proto.float_val).reshape(shape.as_list())
print(f'logits:{outputs}')
小结
该部分基于官方提供的custom estimator的入门指南,记录了从模型开发–>调试–>部署的一个简易闭环流程。
saved_model
上面介绍的是基于封装好的高阶estimator框架进行的,其本质还是基于tensorflow的session进行图运算的。下面看看基于低阶session如何将模型保存成saved_model格式。
SavedModelBuilder
SavedModelBuilder在导出模型时,可自定义inputs、outputs、signature_def(函数名)及tag。相关代码如下:
# construct saved model builder
builder = tf.saved_model.builder.SavedModelBuilder(model_path)
# build inputs and outputs dict,enable us to customize the inputs and outputs tensor name
# when using the model, we don't need to care the tensor name define in the original graph
inputs = {'examples': tf.saved_model.utils.build_tensor_info(model.input_features)}
outputs = {
'class_ids': tf.saved_model.utils.build_tensor_info(model.class_ids),
'logits': tf.saved_model.utils.build_tensor_info(model.logits),
'probabilities': tf.saved_model.utils.build_tensor_info(model.logits_prob)
}
method_name = tf.saved_model.signature_constants.PREDICT_METHOD_NAME
# builder a signature
my_signature = tf.saved_model.signature_def_utils.build_signature_def(inputs, outputs, method_name)
# add meta graph and variables
builder.add_meta_graph_and_variables(sess, [tag],
{key_my_signature: my_signature})
# add_meta_graph method need add_meta_graph_and_variables method been invoked before
# builder.add_meta_graph(['MODEL_SERVING'], signature_def_map={'my_signature': my_signature})
# save the model
# builder.save(as_text=True)
builder.save()
评估及预测时,只需按照保存时定义的协议,进行恢复、取值等相关操作即可(相关命名需和保存时一致),无需关心模型内部细节。相关代码如下:
with tf.Session() as sess:
# load model
meta_graph_def = tf.saved_model.loader.load(sess, [tag], export_model_path)
# get signature
signature = meta_graph_def.signature_def
# get tensor name
in_tensor_name = signature[key_my_signature].inputs['examples'].name
out_tensor_class_ids = signature[key_my_signature].outputs['class_ids'].name
out_tensor_logits = signature[key_my_signature].outputs['logits'].name
out_tensor_probabilities = signature[key_my_signature].outputs['probabilities'].name
# get tensor
# in_tensor = sess.graph.get_tensor_by_name(in_tensor_name)
out_class_ids = sess.graph.get_tensor_by_name(out_tensor_class_ids)
out_logits = sess.graph.get_tensor_by_name(out_tensor_logits)
out_probabilities = sess.graph.get_tensor_by_name(out_tensor_probabilities)
eval_features = sess.run(eval_input)
# 验证是否正常加载了模型参数
dense_2_bias = sess.run('dense_2/bias:0')
dense_1_bias = sess.run('dense_1/bias:0')
# dense_2_bias = sess.graph.get_tensor_by_name('dense_2/bias:0')
# dense_1_bias = sess.graph.get_tensor_by_name('dense_1/bias:0')
# dense_2_bias, dense_1_bias = sess.run([dense_2_bias,dense_1_bias])
print(f'dense_2/bias:0 = {dense_2_bias}')
print(f'dense_1/bias:0 = {dense_1_bias}')
# 批量预测
pre_id = sess.run(out_class_ids, feed_dict={sess.graph.get_tensor_by_name(in_tensor_name): eval_features})
上述完整代码如下: https://github.com/carlos9310/models/blob/master/samples/core/get_started/my_SavedModelBuilder.py
需要注意的是,在预测单个样本时,输入的tensor的每个维度的值对应的特征属性需和训练时的一致,否则会导致实际预测效果很差。在实际输入的时候并没有像estimator那样,将每个值与相关特征属性进行绑定映射(暂时没想到怎么优化这个点)。因此需注意各个值的对应关系。 具体说明如下:
正确的顺序
!saved_model_cli run --dir my_savedmodel/1570873926 --tag_set serve --signature_def serving_default --input_exprs "examples=[[1.7,0.5,5.1,3.3]]"
不正确的顺序
!saved_model_cli run --dir my_savedmodel/1570873926 --tag_set serve --signature_def serving_default --input_exprs "examples=[[5.1,3.3,1.7,0.5]]"
simple_save
上述保存模型的过程代码比较多,tensorflow提供了一个封装好的api(相关参数使用默认值),简化过程(底层依旧使用SavedModelBuilder完成), 相关代码如下:
# simple_save
inputs = {'examples': tf.saved_model.utils.build_tensor_info(model.input_features)}
outputs = {
'class_ids': tf.saved_model.utils.build_tensor_info(model.class_ids),
'logits': tf.saved_model.utils.build_tensor_info(model.logits),
'probabilities': tf.saved_model.utils.build_tensor_info(model.logits_prob)
}
tf.saved_model.simple_save(sess, model_path, inputs=inputs, outputs=outputs)
基于simple_save的完整代码如下: https://github.com/carlos9310/models/blob/master/samples/core/get_started/my_simple_save.py
与SavedModelBuilder的完整代码相比只是模型保存部分更精简,其他一样。
Saver
下面看下如何将训练好的模型保存为checkpoint的格式并从中恢复预测。
保存模型部分很简单,只需实例化一个saver对象,然后调用其save方法将sess中的图保存至相关路径即可。相关代码如下:
saver = tf.train.Saver()
saver.save(sess=sess, save_path=model_path)
预测时,先利用import_meta_graph从*.meta文件(由GraphDef, SaverDef, MateInfoDef,SignatureDef,CollectionDef等组成的MetaGraphDef对象)中恢复出图结构信息,然后从保存的模型文件中恢复权重等数据信息,接着获取图对象,最后基于图对象获取关注的输入输出tensor进行预测即可。相关代码如下:
saver = tf.train.import_meta_graph(model_path + '.meta')
saver.restore(sess, model_path)
# get graph
graph = tf.get_default_graph()
# in this case,we need to know the tensor name define in the graph during training
# and using get_tensor_by_name here
input_features_tensor = graph.get_tensor_by_name('input_features:0')
predicted_classes_tensor = graph.get_tensor_by_name('output/predict_result/predicted_classes:0')
与savedmodel相比,ckpt无法自定义输入输出,实际操作不灵活。
基于Saver的完整代码如下: https://github.com/carlos9310/models/blob/master/samples/core/get_started/my_saver.py
freeze
上述生成的ckpt模型文件中有好多无用的节点,可通过freeze操作进一步瘦身(将*.meta文件中所有Variable节点转换为常量节点)。相关代码如下:
def freeze_and_save_model():
saver = tf.train.import_meta_graph(ckpt_path + '.meta', clear_devices=True)
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
print("%d ops in the input_graph_def." % len(input_graph_def.node))
print([node.name for node in input_graph_def.node])
with tf.Session() as sess:
saver.restore(sess, ckpt_path)
output_node_name = ['output/predict_result/predicted_classes']
output_graph_def = tf.graph_util.convert_variables_to_constants(sess=sess,
input_graph_def=input_graph_def,
output_node_names=output_node_name)
with tf.gfile.GFile(freeze_model_path, 'wb')as f:
f.write(output_graph_def.SerializeToString())
print("%d ops in the output_graph_def." % len(output_graph_def.node))
print([node.name for node in output_graph_def.node])
经过转化后可看出output_graph_def中的节点数比input_graph_def中要少很多。
恢复时,只需从生成的*.pb文件中解析出图对象,然后取相应的tensor节点进行预测即可。相关代码如下:
def load_frozen_model():
with tf.Graph().as_default():
output_graph_def = tf.GraphDef()
with open(freeze_model_path, "rb") as f:
print(f'load frozen graph from {freeze_model_path}')
output_graph_def.ParseFromString(f.read())
tf.import_graph_def(output_graph_def, name="")
with tf.Session() as sess:
input_tensor = sess.graph.get_tensor_by_name('input_features:0')
output_tensor = sess.graph.get_tensor_by_name('output/predict_result/predicted_classes:0')
pre_id = sess.run(output_tensor, feed_dict={input_tensor: [[1.7,0.5,5.1,3.3]]})
print(f'pre_id:{pre_id}')
关于freeze部分的完整代码如下: https://github.com/carlos9310/models/blob/master/samples/core/get_started/my_freeze.py
tensorRT
其是NVIDIA推出的基于自家硬件进行加速推理的工具包。与tensorflow serving类似,其也可部署模型。优化模型并加速推理使其一大亮点。这里简单提一下,以后再更新吧。