Aho–Corasick automaton 算法(简称AC自动机算法)是由Alfred V. Aho和Margaret J.Corasick于1975年在贝尔实验室发明的多模(模式串)匹配算法。即给定多个模式串和一个文本串,求解多模串在文本串中存在的情况(包括是否存在、存在几次、存在于哪些位置等)。
单模匹配
在介绍AC自动机这种多模匹配算法前,先回顾下单模匹配问题,即给定一个文本串和一个模式串,求解模式串在文本串中的匹配情况。
朴素匹配
最直接的想法是暴力(Brute Force)匹配,即将文本串的第一个字符与模式串的第一个字符进行匹配,若相等则继续比较文本串的第二个字符与模式串的第二个字符。若不等,则比较目标串的第二个字符与模式串的第一个字符,依次比较下去,直到得到最后的匹配结果。相关代码如下:
# 每次匹配失败时,文本串T的指针回退到开始匹配位置的下一个位置,模式串P的指针回退到初始位置,然后重新开始匹配
def bfMatch(T,P):
tLen,pLen = len(T),len(P)
indexs = []
for i in range(tLen - pLen + 1):
for j in range(pLen):
if T[i+j] == P[j]:
if j == pLen - 1:
indexs.append(i)
continue
break
return indexs
T='ushershe'
P='he'
print(bfMatch(T,P))
上述匹配过程存在重复匹配,KMP算法优化了上述匹配过程。在匹配失败时,文本串的指针不需要回退。
KMP
与朴素匹配不同,KMP算法在匹配到某个字符失败时,文本串的匹配指针不会回退,模式串则根据部分匹配表(也叫next数组) 向右滑动一定距离后继续与上次在文本串中不匹配的位置进行匹配,若仍不匹配,则继续根据部分匹配表向右滑动模式串,重复上述不匹配–滑动的过程,当匹配指针指到模式串的初始位置依然不匹配,则模式串向右滑动一位,文本串的匹配指针向前移动一位;若匹配,则继续匹配其他位置的字符。当匹配指针连续匹配的字符数与模式串的长度相等,则匹配完成。形象图解可参考字符串匹配的KMP算法。相应代码为:
# 匹配过程中,模式串P中每个待匹配的字符与文本串T中的字符对齐,即匹配指针相同,但两个字符串的下标不同
# 部分匹配表是针对模式串构建的
def kmpMatch(T,P):
tLen,pLen = len(T),len(P)
Next = partialMatchTable(P)
q = 0 # 模式串P的下标
indexs = []
for i in range(tLen):
while q > 0 and P[q] != T[i]:
q = Next[q-1]
if P[q] == T[i]:
q += 1
if q == pLen:
indexs.append(i-pLen+1)
q=0
return indexs
部分匹配表中的数值是指某个子串的前缀和后缀的最长共有元素的长度。 其有两种构建方式。一种是手动法,详见字符串匹配的KMP算法。相关代码如下:
# 手动法求部分匹配表
def partialMatchTable(p): # 也叫next数组
prefix,suffix = set(),set()
pLen = len(p)
Next = [0]
for i in range(1,pLen):
prefix.add(p[:i])
suffix = {p[j:i+1] for j in range(1,i+1)}
common_len = len((prefix & suffix or {''}).pop())
# print(p[:i+1],prefix,suffix,common_len)
Next.append(common_len)
return Next
p='ababaca'
partialMatchTable(p)
另一种是程序法,模式串针对自己的前后缀的匹配。详见KMP算法:线性时间O(n)字符串匹配算法中的部分匹配表部分。相关代码如下:
# 由模式串生成的部分匹配表,其存储的是前缀尾部 的位置。有前缀尾部 = next(后缀尾部),
# 当后缀之后q不匹配时,通过查询部分匹配表,确定前缀尾部的位置k,然后将前缀滑动过来与后缀对齐,继续后续匹配工作
# 程序法计算部分匹配表
def partialMatchTable(p):
pLen = len(p)
Next = [0]
k = 0 # 模式串nP的下标
for q in range(1,pLen): # 文本串nT的下标
while k > 0 and p[k] != p[q]:
k = Next[k-1]
if p[k] == p[q]:
k += 1
Next.append(k)
return Next
p='ababaca'
partialMatchTable(p)
Trie
Trie又叫前缀树或字典树,是一种多叉树结构。Trie这个术语来源于retrieval(检索),其是一种用于快速检索的数据结构。其核心思想是利用字符串的公共前缀最大限度地减少不必要的字符串比较,提高查询(检索)效率,缺点是内存消耗大。
Trie树的基本性质:
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符
- 从根节点到某一个节点,路径上经过的字符连起来为该节点对应的字符串
- 每个节点的所有子节点包含的字符互不相同
应用场景
- 前缀匹配(自动补全):返回所有前缀相同的字符串
- 词频统计:将每个节点是否构成单词的标志位改成构成单词的数量
- 字典序排序:将所有待排序集合逐个加入到Trie中,然后按照先序遍历输出所有值
- 分词
- 检索
多模匹配–AC自动机
有了上述KMP和Trie的背景知识后,对AC自动机会有更加清晰的认识。
AC自动机首先将多模串构建(与Trie树的构建类似)为确定有限状态自动机(DFA),然后按照文本串中的字符顺序依次接收字符,并发生状态转移。【状态中缓存了如下三种情况下的跳转与输出:1.按字符转移成功,但不是模式串的结尾。即成功转移到另一个状态,对应success/goto;2.按字符转移成功,是模式串的结尾。即命中一个模式串,对应emits/output;3.按字符转移失败,此时跳转到一个特定的节点,对应failure。从根节点到这个特定的节点的路径恰好是失败前的文本的一部分,类似KMP算法中利用部分匹配表来加速模式串的滑动从而减少重复匹配】
上述匹配过程只需扫描一遍文本串,其时间复杂度为O(n),与模式串的数量和长度无关。AC自动机可简单看成是在Trie树上通过KMP来实现多模串的匹配。其中Trie树负责状态转移,KMP负责减少重复匹配。
补充:AC自动机中fail路径的构建
AC自动机的构建虽然与Trie树的构建类似,但其fail路径(本质是一种回溯,避免重复匹配)是AC自动机中特有的。具体构建(从离根节点由近及远的节点逐步构建)逻辑为(每个节点都有一条发出的fail路径):
- 1.如果自己是根节点,则指向自己
- 2.如果自己的父节点是根节点,则指向根节点
- 3.找到自己父节点fail路径指向的节点,如果这个节点可以正常接收自己的输入字符,那么就指向这个节点接收自己输入字符后所指向的那个节点
- 4.如果自己父节点fail路径指向的节点不满足,就按第3步的判断,检查自己父节点的父节点的fail路径指向的节点
- 5.一直父节点、父节点、父节点这样的回溯,直到根结点还没找到就指向根节点
以经典的ushers为例,模式串是he、she、his、hers,文本为“ushers”。构建的自动机如图:
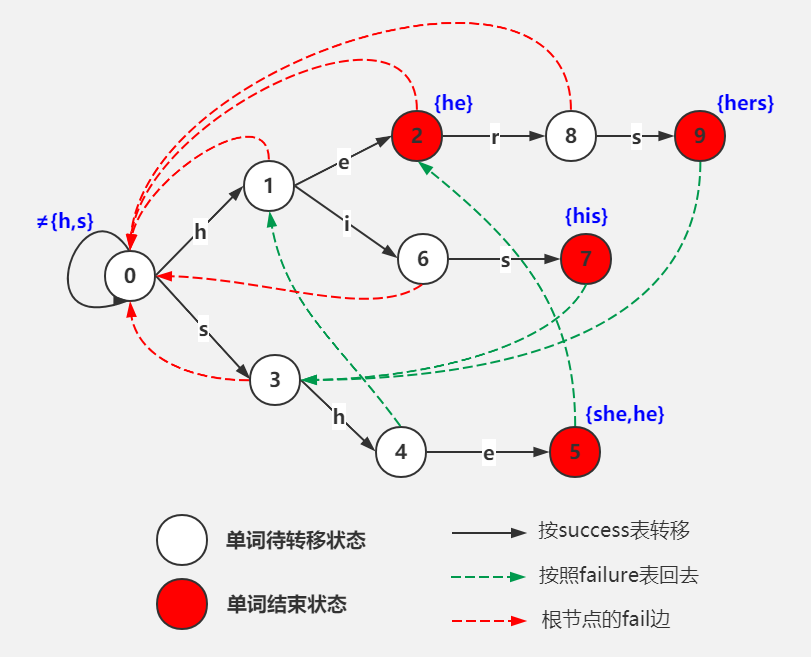
其中实线部分是一颗Trie树,虚线部分为各节点的fail路径。