本篇post主要介绍如何在基于attention机制的seq2seq(Encoder-Decoder)框架中,进一步引入copy机制,使得解码输出更加流畅与准确。
这里主要总结两篇关于copy机制的paper:Incorporating Copying Mechanism in Sequence-to-Sequence Learning与Get To The Point: Summarization with Pointer-Generator Networks。
Incorporating Copying Mechanism in Sequence-to-Sequence Learning
该paper中提出的copyNet使得解码器在解码时能自行决定预测的token是由生成模式还是复制模式而来。其网络结构主要是在Bahdanau attention的基础上进一步增加了copy机制。该机制对于摘要和对话系统来说,可有效提高基于端到端生成文本的流畅度和准确度,并改善了OOV问题。
RNN Encoder-Decoder with attention
首先回顾下基于Bahdanau attention的Encoder-Decoder的过程。
在Encoder端,输入序列被编码成相应的隐状态(向量)序列,其中,为随机初始化的编码器端的隐状态。
在Decoder端,首先根据上一时刻解码器的输出、隐状态以及当前时刻由编码器生成的隐状态序列对应的context向量,更新当前时刻解码器的隐状态。即
然后根据当前时刻解码器的隐状态、上一时刻解码器的输出以及当前时刻由编码器生成的隐状态序列对应的context向量,预测当前时刻解码器的输出,即
其中为随机初始化的解码器端的隐状态,为一种类<START>的特殊的字符,表示一个句子的开始, 表示对encoder端的隐状态(向量)序列进行加权求和,
表示encoder端各个隐状态(向量)序列的权重,表示解码器端上一时刻的隐状态与编码器端的某个隐状态(向量)间的相关性得分,这使得在更新当前时刻解码器的隐状态前,需先计算context向量。
在上述Decoder时,相关变量的迭代顺序:先计算context向量,接着更新Decoder的隐状态,最后估算最有可能的,如此循环。
最终针对一个样本(源序列和目标序列),其目标为最小化如下似然函数:
copyNet
从认知角度看,copy机制就是一种不需要理解内在语义,只需确保文字的外在准确性的一种死记硬背的形式。从模型角度看,copy操作更加生硬,相比上述的注意力机制,其更难集成到一个完全可微的神经网络中。作者们给出了一种基于copy机制且可微的seq2seq模型结构,整体结构如下图所示:
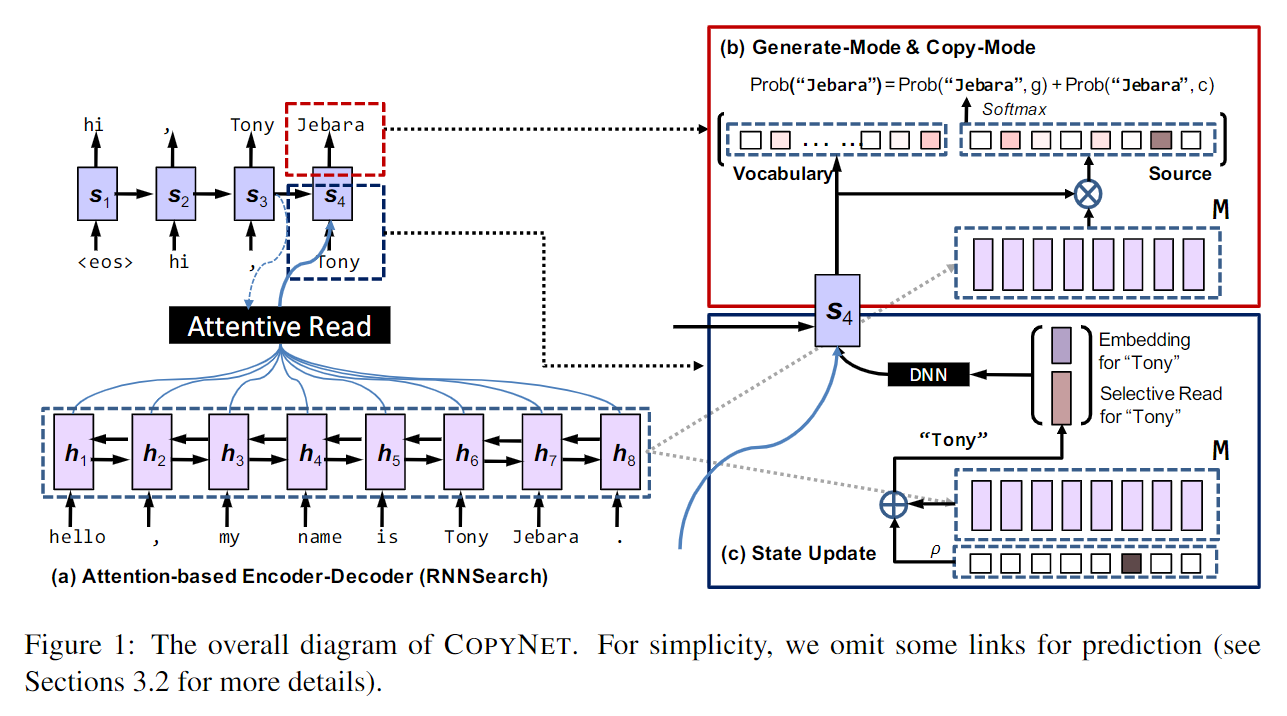
与上述分析的基于attention的Encoder-Decoder相比,最大不同在于Decoder部分,Encoder部分不变。值得指出的是,作者将Encoder端生成的隐状态向量序列定义为copyNet的短期memory,用表示。在解码时将被多次使用。
下面重点对比下copyNet模型中的Decoder部分与上述Decoder部分的不同点。
- Prediction: copyNet在预测某个token时是基于生成模式和copy模式两种混合概率进行建模的,即
- State Update: 在RNN Encoder-Decoder with Bahdanau attention中,当前时刻解码器的状态根据上一时刻解码器的输出、隐状态以及当前时刻由编码器生成的隐状态序列对应的context向量进行更新;而在copyNet中,将替换成的embedding与在输入序列中对应的隐状态向量(若decoder在上一时刻的输出不在encoder的输入序列中,则对应的隐状态向量为零向量)的拼接(此项体现了copy的思想),其它项不变,即
- Reading M: 在解码端更新当前时刻的隐状态时,除了像上述attention机制,每次动态地将encoder端生成的所有隐状态向量序列()表示成(加权求和,attentive read)该时刻对应的context向量外,还会检查解码器上一时刻的输出在输入序列中的位置(同一个词可能会出现多次),然后在中取出(selective read)相应位置对应的隐状态向量,不在的话,对应隐状态为零向量。 的两种读取方式(attentive read与selective read,本质上都是基于注意力进行相关运算的)使得copyNet可以在Generate-Mode与Copy-Mode间进行切换,甚至决定何时开始或者结束copy。Attentive Read就是在编码器端的attention mechanism,Selective Read就是 的计算过程。如果在输入序列中,那么copyNet接下去的输出就很可能偏向Copy-Mode。
上述为copyNet内部结构的大致描述,有关具体变量的详细描述见paper,不再赘述。其整体结构和相关计算与RNN Encoder-Decoder with attention部分很相似,主要不同点在于Decoder部分。
网上找的关于CopyNet的实现。
-
tensorflow: CopyNet Implementation with Tensorflow and nmt
-
pyTorch: An implementation of “Incorporating copying mechanism in sequence-to-sequence learning”
-
Theano: paper作者 incorporating copying mechanism in sequence-to-sequence learning
-
paper中用的文本摘要的公开数据集LCSTS(Large Scale Chinese Short Text Summarization):https://pan.baidu.com/s/1rJC9Vk8e3gF38-mAI5JHPw
Get To The Point: Summarization with Pointer-Generator Networks
该篇paper针对现有基于attention的seq2seq模型做生成式文本摘要的缺点:1、模型可能会错误地生成事实细节;2、模型可能会重复生成某些内容。作者们在原有模型基础上提出了两种改进的方案:1、解码时使用混合的pointer-generator网络结构(思想与copyNet相同,形式不同,相比copyNet,结构更加清晰)。即利用pointer从源文本中copy内容,可有效避免错误事实的生成;利用generator从词表中生成词。pointer-generator结构使模型同时具备了抽取式和生成式摘要的能力; 2、解码输出时增加coverage约束。即在解码时抑制已经在源文本中出现过的内容的attention,可有效消除重复内容的出现。基于改进后的模型在文本摘要任务上可取得较好效果。
Sequence-to-sequence attentional model
这部分内容的计算流程和上述RNN Encoder-Decoder with attention部分大致相同,只是符号有所区别。为了方便与改进后的模型进行对比,给出改进前的模型图:
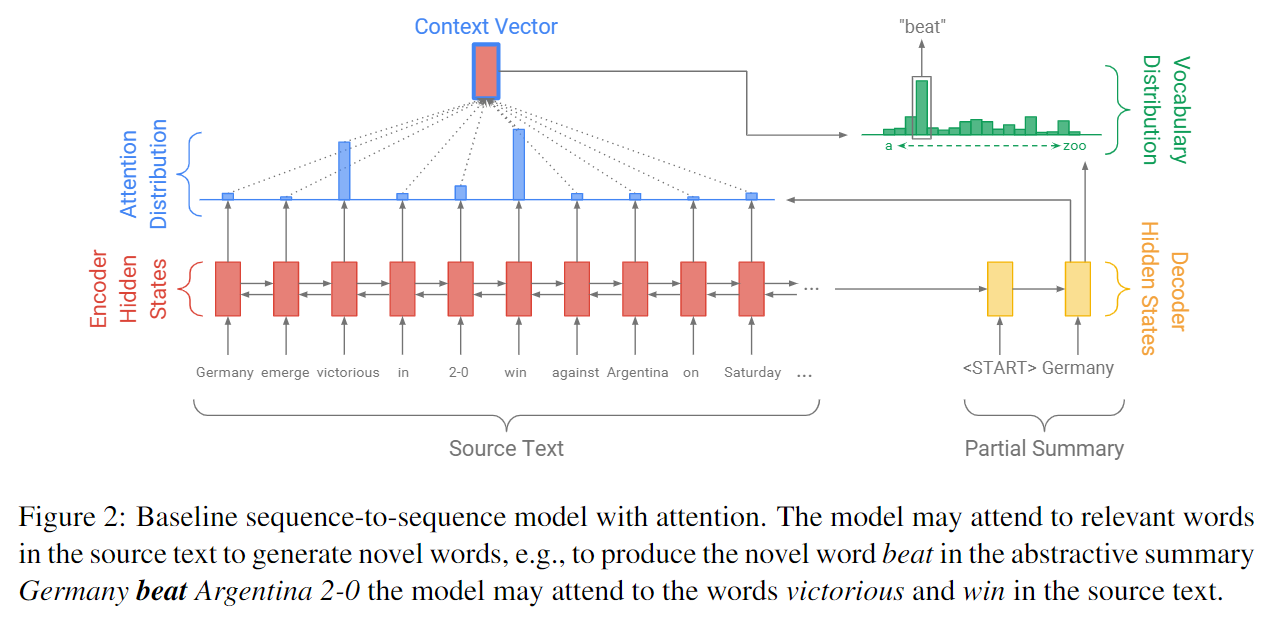
图中在时刻进行解码时有两个概率分布:attention分布和词表分布。
其中表示时刻编码器端每个隐状态向量对应的权重值,且表示解码器端时刻的隐状态向量(paper中写成了t,个人觉得有问题,和Bahdanau不一致)与编码器端第个隐状态向量的相关性得分。
由词表分布可将生成词的概率表示为。
训练期间,在时刻预测目标词对应的loss为:
Pointer-generator network
改进后的模型图:
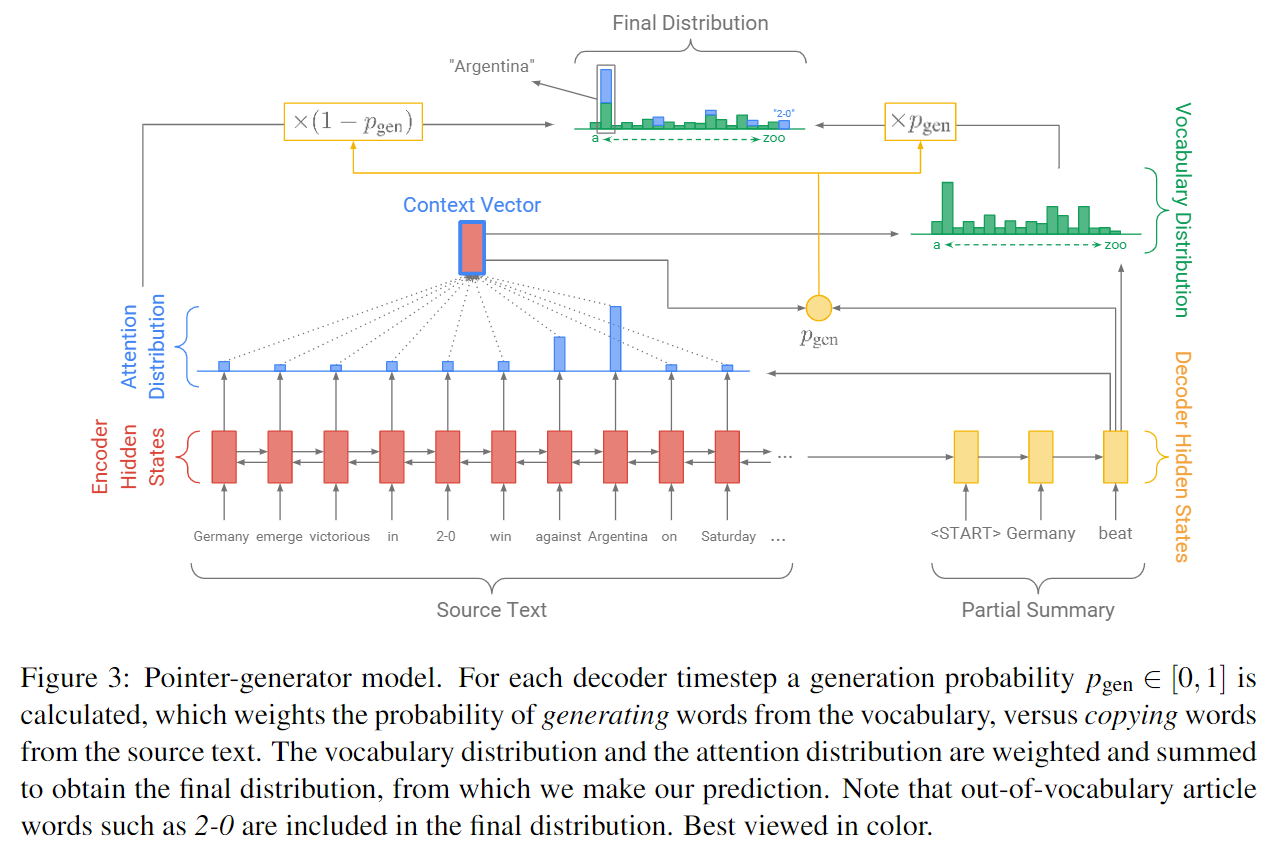
与copyNet类似,Pointer-generator network在解码端预测某个词的概率时,也综合考虑从词表生成(词表分布)和从源输入复制(attention分布)两种情况。 不过其表现形式不同,具体如下:
其中表示生成模式的概率,表示时刻计算的context向量,表示解码器的隐状态,表示解码器的输入,为可学习的模型参数。
说明: 如果词不在词表中,即OOV,则。如果词不在源输入序列中,则。
Coverage mechanism
在生成多句文本序列时,很容易出现内容重复现象。为了消除这种现象,作者们提出了一种coverage机制。具体地,在每一时刻会维持一个coverage向量,其是解码端在之前的各个时刻的attention分布之和,即
其表示到目前时刻为止,源文本输入序列在attention机制下覆盖密度的分布(未归一化)情况。其中为零向量(初始阶段没有覆盖源文本序列的任何词)。
考虑Coverage机制后,在计算解码器端时刻的隐状态向量(paper中写成了t,个人觉得有问题,和Bahdanau不一致)与编码器端第个隐状态向量的相关性得分时,需要同时考虑上述coverage向量。即
这保证了当前的相关性得分参考了之前的权重累积和,从而有效抑制重复内容的出现。同时作者们又定义了一个额外的coverage损失来进一步惩罚在copy时相同位置copy多次的情况。具体损失函数为:
其中。值得指出的是,上述损失函数仅针对每个注意分布和覆盖范围间的重叠进行惩罚,防止重复关注。
基于上述coverage损失,最终加上coverage机制后,训练期间在时刻预测目标词时的loss为
以上便是作者们提出的pointer-generator network + coverage mechanism的思路流程,同时作者也开源了整体模型的实现:Code for the ACL 2017 paper “Get To The Point: Summarization with Pointer-Generator Networks”,不过目前已不再更新且基于python2实现的,本人重新整理了份支持python3的版本:https://github.com/carlos9310/pointer-generator。
参考
-
Incorporating Copying Mechanism in Sequence-to-Sequence Learning
-
Bahdanau attention: Neural machine translation by jointly learning to align and translate
-
Get To The Point: Summarization with Pointer-Generator Networks