深度学习中与分类相关的问题都会涉及到softmax的计算。当目标类别较少时,直接用标准的softmax公式进行计算没问题,当目标类别特别多时,则需采用估算近似的方法简化softmax中归一化的计算。
以自然语言中的语言模型为例,从理论到实践详解基于采样的softmax的近似方法NCE。
理论回顾
逻辑回归和softmax回归是两个基础的分类模型,它们都属于线性模型。前者主要处理二分类问题,后者主要处理多分类问题。事实上softmax回归是逻辑回归的一般形式。
Logistic Regression
逻辑回归的模型(函数/假设)为:
其中为函数,为模型输入,为模型参数,为模型预测输入为正样本(类别为1)的概率,而y为输入对应的真实类别(只有类别0与类别1两种)。其对应的损失函数如下:
上述损失函数称为交叉熵()损失,也叫log损失。通过优化算法(SGD/Adam)极小化该损失函数,可确定模型参数。
Softmax Regression
softmax回归的模型(函数/假设)为:
其中为模型参数,表示第个样本输入属于各个类别的概率,且所有概率和为1。其对应的损失函数如下:
其中表示第个样本的标签值是否等于第个类别,等于的话为1,否则为0。该损失函数与逻辑回归的具有相同的形式,都是对概率取对数后与实际类别的one-hot编码进行逐位相乘再求和的操作,最后记得加个负号。
Noise Contrastive Estimation
由上述softmax的假设函数可知,在学习阶段,每进行一个样本的类别估计都需要计算其属于各个类别的得分并归一化为概率值。当类别数特别大时,如语言模型中从海量词表中预测下一个词(词表中词即这里的类别)。用标准的softmax进行预测就会出现瓶颈。
是基于采样的方法,将多分类问题转为二分类问题。以语言模型为例,利用可将从词表中预测某个词的多分类问题,转为从噪音词中区分出目标词的二分类问题。具体如图所示:
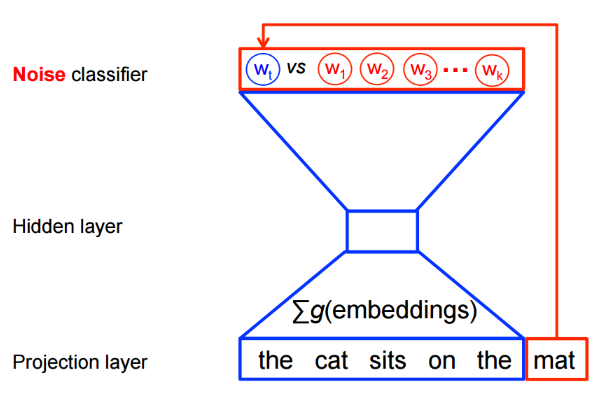
下面从数学角度看看具体如何构造转化后的目标函数(损失函数)
记词的上下文为,为从某种噪音分布中生成的个噪音词(从词表中采样生成)。则构成了正样本(),构成了负样本()。
基于上述描述,可用逻辑回归模型构造如下损失函数
上述损失函数中共有个样本。可看成从两种不同的分布中分别采样得到的,一个是依据训练集的经验分布每次从词表中采样一个目标样本,其依赖于上下文;而另一个是依据噪音分布每次从词表中采样个噪音样本(不包括目标样本)。基于上述两种分布,有如下混合分布时的采样概率:
更进一步地,有
其中为待学习的参数。
又
其中为词的输出embedding。(为词的输入embedding,两个都是待学习的参数)
从定义可知,我们在处理每个样本时仍需对词表中的个词进行归一化操作。而NCE将中需要归一化的分母处理成可学习的参数,从而避免大量的计算。 从实际学习的数值看,每次分母的数值接近1且有较低的方差,实际操作时,可直接设为1。 此时可进一步简化为
则最终正样本的概率为
等价于逻辑回归中的。
由逻辑回归的损失函数可得最终NCE的损失函数为:
备注:NCE具有很好的理论保证:随着噪音样本数的增加,NCE的导数趋向于softmax的梯度。 有研究证明25个噪音样本足以匹配常规softmax的性能,且有的加速。
提示:由上述描述可知,由于每一个目标词往往会采样不同的噪音词,因此噪音样本及其梯度无法存储在矩阵中,从而无法进行矩阵乘法操作。有研究者提出可在小批量的目标词中共享噪音词,从而可利用矩阵运算加速NCE的计算。
Negative Sampling
负采样(NEG)可看成是NCE的近似估计,其并不保证趋向于softmax。因为NEG的目标是学习高质量的词表示,而不是语言模型中的低困惑度(perplexity)。
负采样与NCE一样,也是以逻辑回归的损失函数为目标进行学习的。主要的区别在于将原先NCE的正样本概率表达式
进一步简化为
当是均匀分布(每个词等概率出现)且时,成立,此时,NCE与NEG等价。其他情况,只是近似。
至于为何设成1而不是其他常数,因为可将简化后的概率表达式进一步写成形式:
其他分析流程与NCE相同,不在赘述。
NCE in tensorflow
下面以训练词向量为例(完整代码见tensorflow词向量训练实战或https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/word2vec/word2vec_basic.py),详细解读下tensorflow中是如何实现nce_loss的。
首先是图的构造,这里主要关注tf.nn.nce_loss这个函数的入参,具体说明见源码。
# create computation graph
graph = tf.Graph()
with graph.as_default():
# input data
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
# operations and variables
# look up embeddings for inputs
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# construct the variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
# compute the average NCE loss for the batch.
# tf.nce_loss automatically draws a new sample of the negative labels each time we evaluate the loss.
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights, biases=nce_biases,
labels=train_labels, inputs=embed, num_sampled=num_sampled,
num_classes=vocabulary_size))
在调用tf.nn.nce_loss函数时,只需关注正样本的标签id(labels)、初始mini_batch的词向量(inputs)、负样本个数(num_sampled)、总样本个数,即词表大小(num_classes)以及与NCE相关的两个参数weights、biases。实际训练时,tensorflow内部会像上述描述的那样自动采集负样本,并使实际预测的某个词为正样本的概率较大,而为采集的多个负样本的概率较小。
下面详细看下其内部结构
def nce_loss(weights,
biases,
labels,
inputs,
num_sampled,
num_classes,
num_true=1,
sampled_values=None,
remove_accidental_hits=False,
partition_strategy="mod",
name="nce_loss"):
"""Computes and returns the noise-contrastive estimation training loss.
A common use case is to use this method for training, and calculate the full
sigmoid loss for evaluation or inference.
Note: By default this uses a log-uniform (Zipfian) distribution for sampling,
so your labels must be sorted in order of decreasing frequency to achieve
good results. For more details, see
`tf.nn.log_uniform_candidate_sampler`.
Note: In the case where `num_true` > 1, we assign to each target class
the target probability 1 / `num_true` so that the target probabilities
sum to 1 per-example.
Note: It would be useful to allow a variable number of target classes per
example. We hope to provide this functionality in a future release.
For now, if you have a variable number of target classes, you can pad them
out to a constant number by either repeating them or by padding
with an otherwise unused class.
Args:
weights: A `Tensor` of shape `[num_classes, dim]`, or a list of `Tensor`
objects whose concatenation along dimension 0 has shape
[num_classes, dim]. The (possibly-partitioned) class embeddings.
biases: A `Tensor` of shape `[num_classes]`. The class biases.
labels: A `Tensor` of type `int64` and shape `[batch_size,
num_true]`. The target classes.
inputs: A `Tensor` of shape `[batch_size, dim]`. The forward
activations of the input network.
num_sampled: An `int`. The number of negative classes to randomly sample
per batch. This single sample of negative classes is evaluated for each
element in the batch.
num_classes: An `int`. The number of possible classes.
num_true: An `int`. The number of target classes per training example.
sampled_values: a tuple of (`sampled_candidates`, `true_expected_count`,
`sampled_expected_count`) returned by a `*_candidate_sampler` function.
(if None, we default to `log_uniform_candidate_sampler`)
remove_accidental_hits: A `bool`. Whether to remove "accidental hits"
where a sampled class equals one of the target classes. If set to
`True`, this is a "Sampled Logistic" loss instead of NCE, and we are
learning to generate log-odds instead of log probabilities. See
our [Candidate Sampling Algorithms Reference]
(https://www.tensorflow.org/extras/candidate_sampling.pdf).
Default is False.
partition_strategy: A string specifying the partitioning strategy, relevant
if `len(weights) > 1`. Currently `"div"` and `"mod"` are supported.
Default is `"mod"`. See `tf.nn.embedding_lookup` for more details.
name: A name for the operation (optional).
Returns:
A `batch_size` 1-D tensor of per-example NCE losses.
"""
logits, labels = _compute_sampled_logits(
weights=weights,
biases=biases,
labels=labels,
inputs=inputs,
num_sampled=num_sampled,
num_classes=num_classes,
num_true=num_true,
sampled_values=sampled_values,
subtract_log_q=True,
remove_accidental_hits=remove_accidental_hits,
partition_strategy=partition_strategy,
name=name)
sampled_losses = sigmoid_cross_entropy_with_logits(
labels=labels, logits=logits, name="sampled_losses")
# sampled_losses is batch_size x {true_loss, sampled_losses...}
# We sum out true and sampled losses.
return _sum_rows(sampled_losses)
上述函数主要分为三部分。
_compute_sampled_logits 负责负样本的采样同时计算给定输入样本(上下文),预测词为正样本、采集的num_sampled个负样本的几率。(logits与labels的形状都为[batch_size, num_true + num_sampled])
sigmoid_cross_entropy_with_logits 负责计算交叉熵损失。(sampled_losses的形状为[batch_size, num_true + num_sampled])
_sum_rows 负责求和。(nce_loss最终形状为[batch_size])
后两部分十分简单,重点看下_compute_sampled_logits的内部实现,其是NCE实现的核心。
def _compute_sampled_logits(weights,
biases,
labels,
inputs,
num_sampled,
num_classes,
num_true=1,
sampled_values=None,
subtract_log_q=True,
remove_accidental_hits=False,
partition_strategy="mod",
name=None,
seed=None):
"""Helper function for nce_loss and sampled_softmax_loss functions.
Computes sampled output training logits and labels suitable for implementing
e.g. noise-contrastive estimation (see nce_loss) or sampled softmax (see
sampled_softmax_loss).
Note: In the case where num_true > 1, we assign to each target class
the target probability 1 / num_true so that the target probabilities
sum to 1 per-example.
Args:
weights: A `Tensor` of shape `[num_classes, dim]`, or a list of `Tensor`
objects whose concatenation along dimension 0 has shape
`[num_classes, dim]`. The (possibly-partitioned) class embeddings.
biases: A `Tensor` of shape `[num_classes]`. The (possibly-partitioned)
class biases.
labels: A `Tensor` of type `int64` and shape `[batch_size,
num_true]`. The target classes. Note that this format differs from
the `labels` argument of `nn.softmax_cross_entropy_with_logits_v2`.
inputs: A `Tensor` of shape `[batch_size, dim]`. The forward
activations of the input network.
num_sampled: An `int`. The number of classes to randomly sample per batch.
num_classes: An `int`. The number of possible classes.
num_true: An `int`. The number of target classes per training example.
sampled_values: a tuple of (`sampled_candidates`, `true_expected_count`,
`sampled_expected_count`) returned by a `*_candidate_sampler` function.
(if None, we default to `log_uniform_candidate_sampler`)
subtract_log_q: A `bool`. whether to subtract the log expected count of
the labels in the sample to get the logits of the true labels.
Default is True. Turn off for Negative Sampling.
remove_accidental_hits: A `bool`. whether to remove "accidental hits"
where a sampled class equals one of the target classes. Default is
False.
partition_strategy: A string specifying the partitioning strategy, relevant
if `len(weights) > 1`. Currently `"div"` and `"mod"` are supported.
Default is `"mod"`. See `tf.nn.embedding_lookup` for more details.
name: A name for the operation (optional).
seed: random seed for candidate sampling. Default to None, which doesn't set
the op-level random seed for candidate sampling.
Returns:
out_logits: `Tensor` object with shape
`[batch_size, num_true + num_sampled]`, for passing to either
`nn.sigmoid_cross_entropy_with_logits` (NCE) or
`nn.softmax_cross_entropy_with_logits_v2` (sampled softmax).
out_labels: A Tensor object with the same shape as `out_logits`.
"""
if isinstance(weights, variables.PartitionedVariable):
weights = list(weights)
if not isinstance(weights, list):
weights = [weights]
with ops.name_scope(name, "compute_sampled_logits",
weights + [biases, inputs, labels]):
if labels.dtype != dtypes.int64:
labels = math_ops.cast(labels, dtypes.int64)
labels_flat = array_ops.reshape(labels, [-1])
# Sample the negative labels.
# sampled shape: [num_sampled] tensor
# true_expected_count shape = [batch_size, 1] tensor
# sampled_expected_count shape = [num_sampled] tensor
if sampled_values is None:
sampled_values = candidate_sampling_ops.log_uniform_candidate_sampler(
true_classes=labels,
num_true=num_true,
num_sampled=num_sampled,
unique=True,
range_max=num_classes,
seed=seed)
# NOTE: pylint cannot tell that 'sampled_values' is a sequence
# pylint: disable=unpacking-non-sequence
sampled, true_expected_count, sampled_expected_count = (
array_ops.stop_gradient(s) for s in sampled_values)
# pylint: enable=unpacking-non-sequence
sampled = math_ops.cast(sampled, dtypes.int64)
# labels_flat is a [batch_size * num_true] tensor
# sampled is a [num_sampled] int tensor
all_ids = array_ops.concat([labels_flat, sampled], 0)
# Retrieve the true weights and the logits of the sampled weights.
# weights shape is [num_classes, dim]
all_w = embedding_ops.embedding_lookup(
weights, all_ids, partition_strategy=partition_strategy)
# true_w shape is [batch_size * num_true, dim]
true_w = array_ops.slice(all_w, [0, 0],
array_ops.stack(
[array_ops.shape(labels_flat)[0], -1]))
sampled_w = array_ops.slice(
all_w, array_ops.stack([array_ops.shape(labels_flat)[0], 0]), [-1, -1])
# inputs has shape [batch_size, dim]
# sampled_w has shape [num_sampled, dim]
# Apply X*W', which yields [batch_size, num_sampled]
sampled_logits = math_ops.matmul(inputs, sampled_w, transpose_b=True)
# Retrieve the true and sampled biases, compute the true logits, and
# add the biases to the true and sampled logits.
all_b = embedding_ops.embedding_lookup(
biases, all_ids, partition_strategy=partition_strategy)
# true_b is a [batch_size * num_true] tensor
# sampled_b is a [num_sampled] float tensor
true_b = array_ops.slice(all_b, [0], array_ops.shape(labels_flat))
sampled_b = array_ops.slice(all_b, array_ops.shape(labels_flat), [-1])
# inputs shape is [batch_size, dim]
# true_w shape is [batch_size * num_true, dim]
# row_wise_dots is [batch_size, num_true, dim]
dim = array_ops.shape(true_w)[1:2]
new_true_w_shape = array_ops.concat([[-1, num_true], dim], 0)
row_wise_dots = math_ops.multiply(
array_ops.expand_dims(inputs, 1),
array_ops.reshape(true_w, new_true_w_shape))
# We want the row-wise dot plus biases which yields a
# [batch_size, num_true] tensor of true_logits.
dots_as_matrix = array_ops.reshape(row_wise_dots,
array_ops.concat([[-1], dim], 0))
true_logits = array_ops.reshape(_sum_rows(dots_as_matrix), [-1, num_true])
true_b = array_ops.reshape(true_b, [-1, num_true])
true_logits += true_b
sampled_logits += sampled_b
if remove_accidental_hits:
acc_hits = candidate_sampling_ops.compute_accidental_hits(
labels, sampled, num_true=num_true)
acc_indices, acc_ids, acc_weights = acc_hits
# This is how SparseToDense expects the indices.
acc_indices_2d = array_ops.reshape(acc_indices, [-1, 1])
acc_ids_2d_int32 = array_ops.reshape(
math_ops.cast(acc_ids, dtypes.int32), [-1, 1])
sparse_indices = array_ops.concat([acc_indices_2d, acc_ids_2d_int32], 1,
"sparse_indices")
# Create sampled_logits_shape = [batch_size, num_sampled]
sampled_logits_shape = array_ops.concat(
[array_ops.shape(labels)[:1],
array_ops.expand_dims(num_sampled, 0)], 0)
if sampled_logits.dtype != acc_weights.dtype:
acc_weights = math_ops.cast(acc_weights, sampled_logits.dtype)
sampled_logits += sparse_ops.sparse_to_dense(
sparse_indices,
sampled_logits_shape,
acc_weights,
default_value=0.0,
validate_indices=False)
if subtract_log_q:
# Subtract log of Q(l), prior probability that l appears in sampled.
true_logits -= math_ops.log(true_expected_count)
sampled_logits -= math_ops.log(sampled_expected_count)
# Construct output logits and labels. The true labels/logits start at col 0.
out_logits = array_ops.concat([true_logits, sampled_logits], 1)
# true_logits is a float tensor, ones_like(true_logits) is a float
# tensor of ones. We then divide by num_true to ensure the per-example
# labels sum to 1.0, i.e. form a proper probability distribution.
out_labels = array_ops.concat([
array_ops.ones_like(true_logits) / num_true,
array_ops.zeros_like(sampled_logits)
], 1)
return out_logits, out_labels
下面主要说明该代码涉及NCE的部分。首先通过内置的采样器选取num_sampled个负样本,然后解析采到的负样本编号sampled、期望采到正样本的个数/概率true_expected_count与期望采到负样本的个数/概率sampled_expected_count,(其中每一类的概率服从这样一个分布:
由于word2vec里面每一个word(对应一个class)出现的次数越多,则其对应的class(index)越小,range_max是总类别的数量,可以看出class越小,被取到的几率越大,即越频繁的词被取到的几率越大,会优先选择词频高的词作为负样本。)
接着与mini_batch个正样本编号进行拼接操作(这里mini_batch个正样本共享num_sampled个负样本),然后将拼接后的所有样本编号通过embedding_lookup到weights中选取参数得到all_w(形状为[batch_size + num_sampled, dim]),并将其分成两部分true_w(形状为[batch_size, dim])和sampled_w(形状为[num_sampled, dim])。同样地对biases进行相同的操作,可得all_b(形状为[batch_size + num_sampled])、true_b(形状为[batch_size ])和sampled_b(形状为[num_sampled])。
接下来便是true_logits与sampled_logits的计算了。
对于true_logits,首先将隐层输出inputs(形状为[batch_size, dim])与true_w变形后进行逐位相乘,经过一系列变换操作后得到true_logits,再与true_b相加,同时从中减去true_expected_count的对数。(https://www.tensorflow.org/extras/candidate_sampling.pdf中有说明)
对于sampled_logits,首先将隐层输出inputs(形状为[batch_size, dim])与sampled_w进行矩阵乘法操作,再与sampled_b相加,同时从中减去sampled_expected_count的对数。(https://www.tensorflow.org/extras/candidate_sampling.pdf中有说明)
最后将得到的true_logits与sampled_logits进行拼接得到最终的out_logits,同时构造相应的out_labels(形状为[batch_size, num_true + num_sampled],其中num_true对应的列为1(正样本),num_sampled对应的列为0(负样本))。