总结在不同场景下评价一个模型时的常用指标。(在测试集上)评估时基本都会以ground truth(基本事实)为依据。
分类
accuracy
准确率(accuracy) = 正确预测的样本数/预测的总样本数
说明: 在样本不平衡的情况下,该指标基本没有参考价值。如在fraud detection(欺诈检测)、癌症检测等正负样本分布不平衡的案例中,如果分类器将所有样本都分成负样本,其可以获得较高的准确率,但少数的正样本一个都没有检测出来!!!【一般用异常样本(如欺诈行为、癌症特征)表示正样本】
precision
精确率(precision) = 正确预测的正样本数/预测为正样本的总数
精确率也叫查准率,更关注准确性。 如在检测垃圾邮件的场景中,通常要求模型有更高的准确性(预测的样本中出错的可能性要小)。即正常邮件(负样本)不能误判为垃圾邮件(正样本)。
recall
召回率(recall) = 正确预测的正样本数/实际为正样本总数
召回率也叫查全率,更关注全面性。 如在检测肿瘤、地震等场景中,通常要求模型有更高的全面性(预测的样本中尽可能多地预测为正样本)。即不能漏检肿瘤、地震等正样本。
precision与recall是一对矛盾的度量。常常一个比较高时另一个就比较低,因此单一的precision或recall不能准确地衡量分类器的性能。 通过权重系数(表示recall的重要性是precision 倍)综合考虑precision与recall两个指标。当时,recall更重要;当时,precision更重要。具体计算公式如下:
实际中常取。
ROC
ROC(Receiver Operating Characteristic,接收器工作特性)曲线是一种在类别不平衡问题中评估二分类模型性能的常用方法。
首先介绍下混淆矩阵中Positive、Negative、True、False的概念
- 预测类别为1的是Positive(阳性),预测类别为0的是Negative(阴性)
- 预测正确用True(真)表示,预测错误用False(伪)表示
具体混淆矩阵如下:
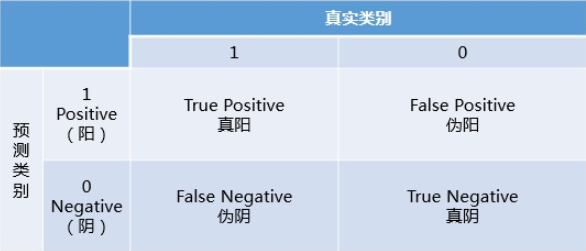
其中行表示预测类别的分布,列表示真实类别的分布。
由此引出True Positive Rate(真阳率,和recall的定义相同)、False Positive Rate(伪阳率)两个概念:
-
$TPR=\frac{TP}{TP+FN}$
-
$FPR=\frac{FP}{FP+TN}$
由定义可知,是除以所在的列(真实类别为1的所有样本数),是除以所在的列(真实类别为0的所有样本数)。即
- (真阳率)表示在所有真实类别为1的样本中,预测类别为1的比例
- (伪阳率)表示在所有真实类别为0的样本中,预测类别为1的比例
有了上述预备知识,就比较好理解ROC和AUC(ROC下的面积)了。
ROC以为横轴,以为纵轴。当两者相等时,表示无论真实类别是1还是0的样本,分类器将其预测为1的概率是相等的,即分类器对正例和负例样本毫无区分能力。因此一般来说的最小值为0.5。
我们希望分类器达到的效果是:对于真实类别为1的样本,分类器预测为1的概率(即)要远大于真实类别为0的样本,分类器预测为1的概率(即)。最理想的情况是一直为1,即的最大值为1。
具体绘制ROC曲线的方法:
- 对于预测类别为离散标签,经统计得到混淆矩阵,从而算出一组与,描点求面积可得AUC
- 对于预测类别为概率的分类器,依此使用所有的预测值作为阀值,根据得到的不同的混淆矩阵计算出一系列与,描点求面积可得AUC
由上述分析过程可知,ROC对类别分布不敏感,即使正负例的比例发生了较大变化,ROC也不会产生大的变化。在计算AUC时,同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。 但是由于ROC对类别分布不敏感,当负例增加时,曲线却没怎么变,等价于FP增多了。即虽然负例被预测成正例的数量增多了,但在ROC曲线上无法直观地(体现)看出来。 在类别不平衡问题中,ROC会给出一个比较乐观的估计。
在计算AUC时,除了通过ROC下的面积计算,还可通过如下方法: 假设总共有m+n个样本,其中正样本m个,负样本n个,总共有mn个样本对,统计将真实正样本预测为正样本的概率值大于将真实负样本预测为正样本的概率值的样本对的个数,然后除以mn就是AUC的值。
详细解释: 对于任意的一个样本,分类器将其预测为正样本的概率为p。在一批已知正负样本的集合中,按分类器的预测概率从高到低对样本集进行排序,对于正样本中概率最高的,排序为rank_1(概率越大,排序值越大),比它概率小的有m-1个正样本,rank_1-m个负样本。正样本概率第二高的,排序为rank_2,比它概率小的有m-2个正样本,rank_2-m+1个负样本。以此类推,正样本中概率最小,排序为rank_m,比它概率小的有0个正样本,rank_m-1个负样本。总共有m*n个正负样本对。在所有正负样本对中,正样本概率大于负样本概率的个数为rank_1-m+rank_2-m+1+…+rank_m-1。化简后的AUC计算公式为:
AUC的本质: 从所有正例中随机选取一个正样本A,再从所有负例中随机选取一个负样本B,分类器将A预测为正例的概率比将B预测为正例的概率还要大的可能性。AUC反映了分类器对样本的排序能力,即将正样本排在负样本前面的概率就是AUC的值。
PR
PR(Precision - Recall)曲线以Precision为纵坐标,以Recall(TPR)为横坐标。与ROC一样,PR曲线也可以使用AUC来衡量分类器的效果。但ROC综合考虑了正负样本的分类情况,而PR曲线的两个指标都聚焦于正例。在类别不平衡问题中,由于主要关心正例,因此在此情况下PR曲线的效果要优于ROC曲线。
参考
聚类
回归
推荐
搜(检)索
生成
包括但不限于翻译、摘要、对话、机器阅读理解(MRC)、问答等